Large Language Models (LLMs) sind in aller Munde, aber kaum jemand versteht, wie sie funktionieren. Es gibt einige ganz gute Explainer in englischer Sprache, aber keine wirklich guten in Deutsch (jedenfalls ist mir keiner untergekommen).
Dies ist ein Auszug aus der Literaturstudie: „Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft“, die ich für die Hans-Böckler-Stiftung erstellt habe. Ich habe den Erklärteil zu LLMs herausgelöst, um ein breiteres Verständnis für die Technologie zugänglicher zu machen.
Begriffe zur Einführung
Künstliche Intelligenz (KI) ist ein Feld der Informatik, das fast so alt ist wie die Informatik selbst. In der KI geht es darum, Computer dazu zu bringen, auf bestimmte Arten zu agieren, die von Menschen als intelligent empfunden werden. Das schließt unter anderem die Lösung von komplexen Problemen, das selbstständige Lernen von neuen Fähigkeiten und auch die Beherrschung der menschlichen Sprache mit ein.
Künstliche Neuronale Netzwerke (KNN) sind die derzeit meistverwendete Technologie im Feld der KI. KNN bestehen aus künstlichen Neuronen und sind von den neuronalen Netzwerken im Gehirn von Menschen und Tieren inspiriert. KNN werden in einem Prozess namens „Deep Learning“ oder auch „maschinelles Lernen“ mit großen Datenmengen trainiert und erlangen dadurch Fähigkeiten, die schwer wären, durch normale Programmierung herzustellen; etwa das Erkennen von Objekten, Menschen oder Katzen, oder die Fähigkeit, Texte zu generieren, die Texten menschlichen Ursprungs ähneln.
Natural Language Processing (NLP) ist das Feld der KI, das sich dem maschinellen Analysieren, Transformieren und Generieren von natürlicher Sprache widmet.
Large Language Models (LLM) sind Künstliche Intelligenzen, die auf das Gebiet von NLP spezialisiert sind und aufgrund ihrer beachtlichen Fähigkeiten zur aktuell breit geführten Debatte um KI beigetragen haben. LLMs basieren auf KNN und sie stehen im Fokus dieser Literaturstudie.
Generative Pre-Trained Transformer (GPT) sind die derzeit populärsten LLM-Systeme. Die Firma OpenAI hat mit ihrem Chatbot ChatGPT und Modellen wie GPT-4 derzeit den größten Erfolg. Obwohl auch die meisten anderen LLMs technisch zu den GPTs gezählt werden können, verwendet vor allem OpenAI den Begriff für seine Systeme.
Tokens sind in ganze Zahlen umgewandelte Worte oder Wortbestandteile, wobei jedem Wort eine feststehende Zahl zugewiesen ist. Wenn LLMs trainiert werden, müssen die Trainingsdaten in Tokens umgewandelt werden. Wenn LLMs Sprache verarbeiten oder generieren, verarbeiten sie Tokens und generieren Tokens, die am Ende wieder in Worte umgewandelt werden.
Parameter sind die gewichteten Verbindungen zwischen den künstlichen Neuronen in KNN. In den Parametern liegen die Informationen gespeichert, mit denen eine KI, die auf KNN basiert, arbeitet. Die Anzahl der Parameter gibt eine ungefähre Vorstellung von der Größe und Komplexität und damit auch Leistungsfähigkeit einer KI.
Das Kontext-Fenster (Context Window) umfasst bei LLMs den Kontext eines aktuell zu generierenden Wortes. Da LLMs immer nur das nächste Wort vorhersagen, geschieht diese Vorhersage unter Einbezug aller vorher geschrieben Worte (Tokens), inklusive der Eingabe der Nutzer*innen. Das Kontext-Fenster fungiert somit wie der Arbeitsspeicher eines LLM.
OpenAI ist die Firma, die die derzeit erfolgreichsten und bekanntesten LLMs wie GPT-3.5 und GPT-4 über den Chatbot ChatGPT bereitstellt. Sie wurde 2015 als Non-Profit gegründet, um einen offenen und ethischen Ansatz der KI-Entwicklung zu verfolgen, aber agiert seit 2019 als gewinnorientiertes Startup, das mit Investorengeld Produkte entwickelt und seine wichtigsten Technologien geheim hält. Seit dieser Zeit ist es auch operativ und finanziell eng an Microsoft gebunden.
Es werde das nächste Wort
LLMs sagen immer nur das nächste Wort voraus. Das klingt trivial und ein bisschen so, wie die Wortvorschläge beim Nachrichten-Tippen auf dem Smartphone. Der wesentliche Unterschied zu dieser recht einfachen Technologie besteht darin, dass das Smartphone für eine Wortvorhersage nur vom letzten geschriebenen Wort aus rät. LLMs nehmen dagegen die gesamte Sequenz an geschriebenen Worten als Ausgangspunkt für die Vorhersage.1
Es ist leicht, nach dem Wort „Ich“ ein „bin“ vorherzusagen. Aber wie wird das nächste Wort nach dem Satz, den sie gerade lesen, sein? Wie wird der der Absatz, oder der gesamte Text dieser Studie zu Ende gehen? Natürlich unter Berücksichtigung seiner gesamten bisherigen Struktur, seiner Argumente, dem Schreibstil in dem er verfasst ist, sowie den gesamten Kontext des zu behandelten Themas? An dieser Aufgabe kann man nur scheitern. Aber heute scheitern LLMs besser an dieser Aufgabe als viele Menschen.
Doch was heißt „besser“ in diesem Zusammenhang? Das qualitative Urteil, das an Sprachmodelle herangetragen wird, ist eines der Täuschung. Wenn ein LLM gut ist, meinen wir, dass ihre Resultate uns überzeugen könnten, von einem Menschen verfasst zu sein (Natale 2021). Dazu wurde das System mit Millionen von Menschen geschriebenen Texten gefüttert, die es statistisch durchmessen hat, sodass es anhand dieser Statistik die Wahrscheinlichkeit des nächsten Wortes in einem Satz, Absatz oder Text vorhersagen kann.
In diesem Prozess der statistischen Durchforstung endloser Textmengen hat die Maschine „gelernt“, wie Worte sich statistisch zueinander verhalten. Sprache ist vielseitig und komplex, doch in ihr gibt es auch eine ganze Menge Regelmäßigkeiten. Das LLM lernt z.B. schnell die Regel, dass auf ein Subjekt irgendwann ein Prädikat und dann irgendwann ein Objekt folgt. Das LLM lernt Grammatik, ohne, dass ihm jemand die Subjekt-Prädikat-Objekt-Regel explizit einprogrammieren müsste. Syntaktik und Grammatik sind statistisch vergleichsweise leicht abzuleiten; sie sind so einfach, dass wir sie sogar sie in expliziten Regeln aufschreiben konnten.
Es gibt aber auch eine Menge Regeln bzw. Regelmäßigkeiten in der Sprache, die wir bislang noch gar nicht formell festgehalten haben, weil sie so komplex sind. Nehmen wir den Satz: „Die Wirtschaft spaziert Aschenbecher in der Nadel.“ Das ist ein grammatikalisch wohlgeformter Satz, aber er macht keinen Sinn. Wir können zwar erklären, warum dieser Satz keinen Sinn ergibt, aber wir haben keine allgemeinen Regeln dafür, wie man sinnhafte Sätze formt.
Der überraschende Erfolg der LLMs basiert darauf, dass sie auch semantisch korrekte Sätze zu formen imstande sind. Sprachmodelle kamen bislang immer dort an ihre Grenze, wo die Satzkonstruktion ein gewisses Verständnis des Inhalts erfordert. Etwa bei hierarchischen Satzkonstruktionen wie: „Die Schlüssel zum alten, moderigen Schuppen lagen auf dem Tisch“. Es erfordert ein Verständnis des Inhaltes des Satzes, um das Verb „lagen“ (Mehrzahl, Vergangenheitsform) richtig zu bilden, weil es sich auf das weit zurückliegende „Schlüssel“ bezieht (Mahowald et al. 2023).
Es ist rechnerisch leicht, eine Wahrscheinlich für das Wort nach einem anderen Wort zu berechnen. Man nennt solche Wortpaare „2Grams“. Schon deutlich schwieriger wird es, wenn man ein 3Gram berechnen will, d.h. von zwei Worten aus das dritte zu berechnen. Auf einmal hat man zwei abhängige Variablen, die es zu berücksichtigen gilt und mit jedem zusätzlichen Wort steigen die nötigen Rechenoperationen exponentiell.
Nun könnte man sich vorstellen, aus den gesamten Trainingsdaten die vorkommenden n-grams (n steht für die Anzahl der verkoppelten Worte) zu bilden und zu speichern. Man erhielte eine verlustfreie Kopie der Trainingsdaten. Jedoch würde so eine Prozedur schnell die Rechenkapazitäten aller verfügbaren Computer der Welt sprengen.
Was man stattdessen macht, ist das, was man immer macht, wenn die Realität für die Verarbeitung zu komplex ist: Man macht ein Modell. Ein Modell ist immer eine Annäherung an die Realität, die nicht perfekt, aber für bestimmte Zwecke gut genug ist. LLMs können also wortwörtlich als ein Modell der menschlichen Sprache verstanden werden, so wie eine Modelleisenbahn ein Modell einer wirklichen Eisenbahn ist. So wie eine Modelleisenbahn sich bemüht, alle möglichen Details der Eisenbahn abzubilden, so versucht ein LLM alle möglichen Details von Sprache abzubilden, aber ist dabei, wie die Modelleisenbahn, eben nur so gut, wie es die Technik gerade zulässt.
Das hat einige Implikationen. Wären die Trainingsdaten in n-grams gespeichert, wäre ein LLM in der Lage, alle Fakten, Quellen und Zitate der Trainingsdaten Buchstabe für Buchstabe wiederzugeben. Weil ein LLM aber nur ein Modell der Sprache ist, klappt das nur manchmal.
In den Daten klaffen Lücken und das Modell ist besonders kompetent darin, diese Lücken so zu füllen, dass es so aussieht, als seien da gar keine Lücken. So kommt es vor, dass es enorm selbstsicher formulierte Sätze ausgibt, deren Fakten ausgedacht sind und sie beim genauen Hinschauen teils überhaupt keinen Sinn ergeben. Man spricht dann z. B. davon, dass LLMs „halluzinieren“. Was sie aber eigentlich tun, ist die Lücken zu füllen mit Worten, die statistisch plausibel hineinpassen.
Ted Chiang, Autor beim Magazin The New Yorker, brachte diese Modellhaftigkeit der Sprachmodelle gut auf den Punkt, indem er sie mit JPEGs verglich. (Chiang 2023) JPEG ist so etwas wie das Standardformat für Fotos im Internet und ist bekannt für seine enorm effektive, aber verlustreiche Kompression. Speichert man seine Fotos im JPEG-Format, lassen sich eine Menge Daten sparen, doch schaut man genauer auf die Details in den Fotos, fallen einem die verschwommenen Fragmente an den Rändern von Konturen ins Auge. ChatGPT sei ein verschwommenes JPEG des Internets, so der Autor.
JPEGs sind für viele Zwecke ungenügend, vor allem Profis greifen lieber auf verlustfreie Kompressionsformate zurück. Dennoch haben JPEGs einen enormen Nutzen und das gilt offenbar auch für LLMs, zumindest wenn man ihre Stärken und Schwächen kennt. Wie immer gilt der Ausspruch von George Box: „Alle Modelle sind falsch, aber manche sind nützlich.“ (Box 1979, S. 202).
Kontext: Die Deep-Learning-Revolution vor zehn Jahren
Das Training von LLMs ist sehr gradlinig. Man gibt der Maschine einen Teil von einem Text und bittet sie, das nächste Wort zu ergänzen. Dann vergleicht man das geratene Wort mit dem tatsächlich im Text folgenden Wort, errechnet den Fehlerwert und gibt das Ergebnis an das System zurück, das die Information dazu verwendet, seine Vorhersagefähigkeiten zu verbessern.
Am Anfang wird die Maschine noch irgendwelche zufälligen Wörter vorschlagen, die nicht mal ansatzweise Sinn ergeben. Etwa „Ich Tasse“ oder „Mensch rot“. Die dadurch ausgelösten negativen Feedbacksignale helfen aber jedes Mal ein kleines Stück, das System zu verbessern. Je öfter das System diesen Prozess durchgemacht hat – wie sprechen hier von Hunderte Milliarden Mal – desto besser wird es im Raten.
Das dahintersteckende Verfahren ist sehr viel älter als die aktuellen Sprachmodelle und nennt sich „Deep Learning“. Beim Deep Learning geht es darum, mittels großer Datenmengen ein künstliches neuronales Netz zu trainieren. KNN sind von natürlichen neuronalen Netzen wie die Gehirnstrukturen von Menschen und Tieren inspiriert.2
Die ersten künstlichen Neuronen im sogenannten „Perceptron“ von 1958 waren tatsächlich noch Hardware-Relais, die mit Drähten verbunden waren (Loiseau 2019). Experimente mit KKN auf Softwarebasis wurden seit den 1970er-Jahren immer wieder gemacht, doch bis auf wenige Einsatzzwecke z. B. in der E-Mail-Spamerkennung hatte der Ansatz nur wenig Relevanz.
Erst im Jahr 2012 gelang der Durchbruch. Bis dahin gab es unterschiedliche Ansätze, Künstliche Intelligenz voranzubringen, etwa symbolische Systeme oder Expertensysteme. Bei diesem Ansatz versuchen Menschen die zu lösenden Aufgaben in Form von Regeln zu definieren und diese Regeln als Code im KI-System zu implementieren. Das war noch bis 2010er-Jahre hinein einer der wichtigsten KI-Ansätze.
Das änderte sich mit der „ImageNet Challenge“ von 2012, einem Wettbewerb in künstlicher Bilderkennung. Damals hatte sich das Team unter der Leitung von Geoffrey Hinton mit einem „Deep Neural Net“ (ein anderer Name für KNN) namens AxelNet mit großem Abstand zu allen anderen Bewerbern durchgesetzt. Seitdem dominieren KKN das gesamte Feld von KI und selbstlernender Systeme, nicht nur in der Bilderkennung.
Die künstlichen Neuronen eines KNN sind in mehreren Ebenen („layers“) angeordnet, und zwischen den Ebenen durch künstliche Synapsen miteinander verbunden. Die erste Ebene ist die Input-Ebene, also die Reihe von Neuronen, auf die die eingehenden Daten treffen. Am Ende steht die Output-Ebene, die das Ergebnis der Berechnung liefern soll: ist ein Hund oder Katze auf dem Bild, oder was ist das nächste Wort?
Zwischen Input und Output sind mehrere sogenannte „versteckte Ebenen“ („hidden layers“) geschaltet, die die eigentliche Informationsprozessierung handhaben. Grob gesagt kann ein künstliches Neuronales Netz mit mehr versteckten Ebenen komplexere Aufgaben bewältigen und je mehr versteckte Ebenen es gibt, desto aufwendiger sind die Durchläufe durch das Netz.
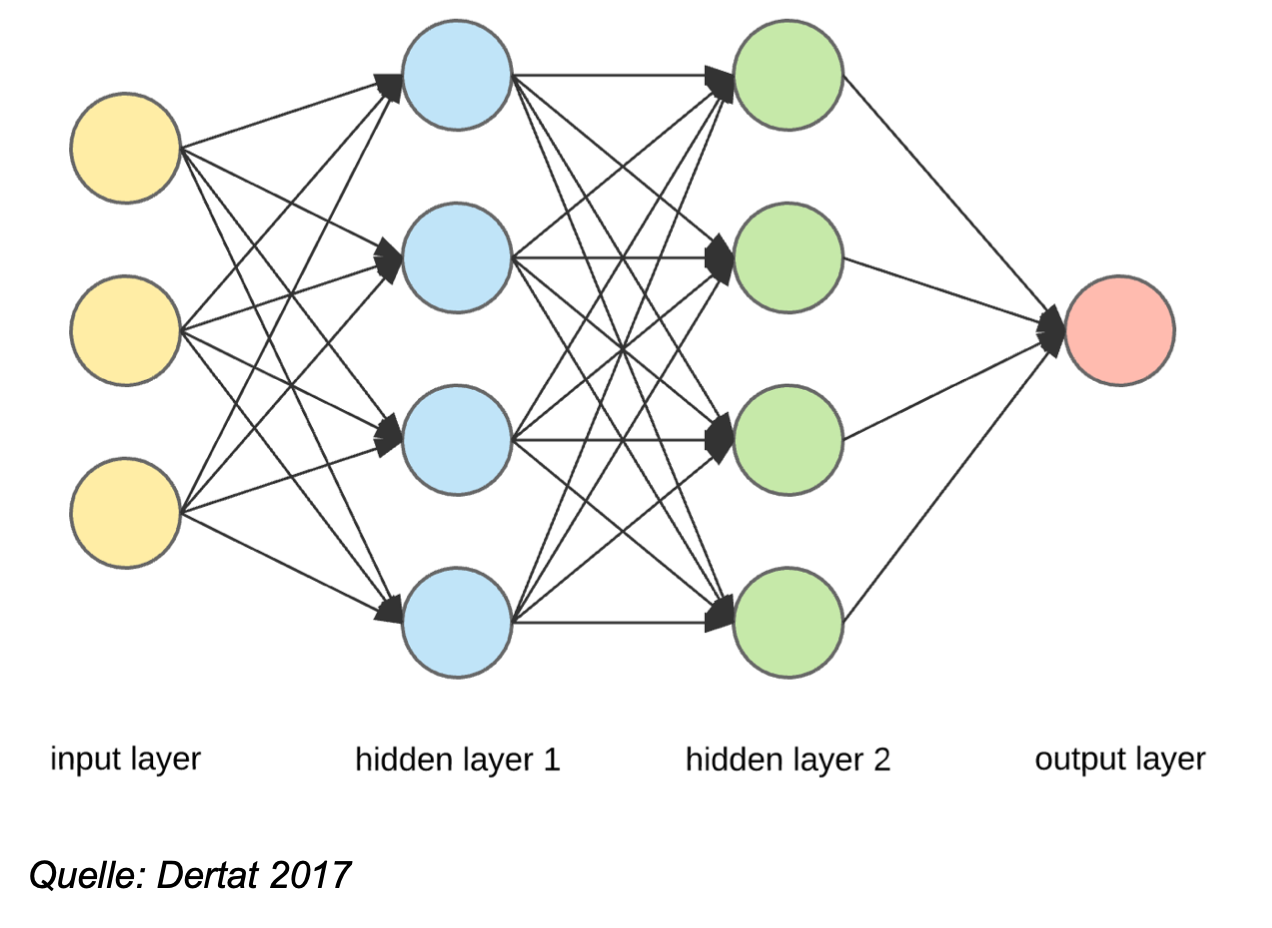
Treffen Daten auf die Input-Ebene, entscheiden die einzelnen Neuronen jeweils anhand einer integrierten Funktion, ob und wie stark sie das Signal an die dahinterliegende versteckte Ebene weiterreichen sollen. Die Neuronen der versteckten Ebene haben ebenfalls eine Funktion, um zu entscheiden, wie die eintreffenden Signale der Input-Ebene gedeutet werden sollen und geben davon abhängig ihrerseits ein Signal an die Neuronen der nächsten versteckten Ebene weiter.
Und so wandern die vom Input ausgelösten Signale von Ebene zu Ebene, wobei jedes Neuron von sich aus entscheidet, welchen Output es auf welchen Input hin weitergibt. Je weiter sich die Signale durch die versteckten Ebenen arbeiten, desto abstraktere Informationen werden für gewöhnlich verarbeitet.
Hier ein vereinfachtes Beispiel für eine Bilderkennung: Die Input-Ebene bekommt ein Bild und teilt es in Bereiche für ihre Neuronen auf. Die erste versteckte Ebene identifiziert darin Kontraste, die zweite Ebene interpretiert die Kontraste und erkennt Formen, die dritte Ebene fügt die Formen zu einer Gesamtkomposition zusammen und die Output-Ebene gibt Wahrscheinlichkeitswerte aus, welchen Objekten die Gesamtkompo-sition ähnlich sieht. Jeder Input durchläuft das gesamte neuronale Netzwerk, bis es an der Output-Ebene zu einer Entscheidung kommt.3
Befindet sich das neuronale Netz im Trainingsprozess, wird ihm nach jedem Durchlauf zurückgespiegelt, ob es richtig lag. Dieses Feedback wird dann wiederum im ganzen Netzwerk verarbeitet, nur läuft es diesmal rückwärts. Dabei errechnet eine sogenannte „Verlust-Funktion“ (Loss Function), wie weit das Netzwerk vom richtigen Ergebnis entfernt lag.
Bei einer falschen Bilderkennung schaut die Output-Ebene, welche Verbindungen (Parameter), der letzten versteckten Ebene dazu beitrugen, die falsche Entscheidung zu treffen und reduziert ihre Relevanz durch Anpassung der Gewichtungen. Dasselbe tut die versteckte Ebene mit ihrem Vorgänger, und diese wiederum mit ihrem Vorgänger und so weiter, bis hin zur Input-Ebene.
Dieses automatische Einarbeiten von Feedback durch das ganze Netz nennt man „Backpropagation“ und ist zentraler Bestandteil aller heutigen KNN, inklusive der LLMs. Dabei steht die Minimierung der Verlust-Funktion im Zentrum. Wenn der errechnete Verlustwert nicht mehr sinkt, ist das Netzwerk im Rahmen der gegebenen Möglichkeiten fertig trainiert.
Dass der Durchbruch dieser Technologie erst im Jahr 2012 erfolgte, obwohl daran seit den 1970er-Jahren geforscht wird, lag an zwei Faktoren: Zum einen können derart signifikante Ergebnisse nur mit einer enormen Menge von Trainingsdaten erzielt werden, so vielen Daten, wie sie vor der massenweisen Verwendung des Internets den Wenigsten zur Verfügung standen.
Der zweite Faktor war, dass das Training eines neuronalen Netzwerks ab einer bestimmten Komplexität enorme Rechenkapazitäten erfordert. Durch die Popularisierung von Videospielen standen ab den 2010er-Jahren leistungsfähige Grafikprozessoren (GPUs) zur Verfügung, die bestimmte Berechnungen schneller als herkömmliche Prozessoren und dazu noch parallel durchführen konnten.
Durch diese beiden Faktoren konnten immer komplexere Modelle mit immer mehr versteckten Ebenen auf noch mehr Daten trainiert werden, und dieses Skalieren von Ebenen, Parametern und Trainingsdaten führt bis heute zu immer neuen Fähigkeiten von KNN.
Der Trainingsprozess: Einbettung im latenten Raum
Auch die heutigen LLMs, basierend auf dem Transformermodell (dazu gleich mehr), müssen trainiert werden. Zuvor müssen allerdings die Trainingsdaten bereitgestellt und bearbeitet werden. LLMs sind mit Billionen von Wörtern trainiert und die müssen erstmal gesammelt werden. Dabei spielt das Internet eine wichtige Rolle. Selbst riesige Textsammlungen wie die Wikipedia oder die Summe aller digitalisierten Bücher machen nur einen Bruchteil der Trainingsdaten aus. Der größte Teil der Texte kommt aus rudimentär gesäuberten Datensammlungen, die im Grunde aus Millionen beliebig zusammengesuchten Websites bestehen.4
In einem zweiten Schritt müssen diese Trainingsdaten für das Modell in Tokens umgewandelt werden. Dafür gibt es sogenannte Tokenizer, also Programme, die jedem Wort oder Wortbestandteil, eine ganze Zahl zuordnen. Mit jedem Token wird dann ein vieldimensionaler Vektor verknüpft – ein sogenanntes „Embedding“ – eine „Einbettung“ in den Kontext aller anderen Tokens. Im Embedding sind alle Beziehungen eines Tokens zu allen anderen Tokens gespeichert. Zu Beginn des Trainings ist dieser Vektor allerdings noch mit rein zufälligen Werten belegt.
Wenn das Modell im Laufe des Trainings dann für jede Abfolge von Tokens den jeweils nächsten Token rät, wird die Vorhersage mit dem Ergebnis des tatsächlich nächsten Tokens in den Trainingsdaten verglichen und die Abweichung der Verlust-Funktion per Back-Propagation durch das Netzwerk zurückgefüttert. Im Zuge dieses Lernprozesses werden nicht nur die Verbindungen neu gewichtet, sondern es werden auch mit jedem Schritt die Embeddings der Tokens aktualisiert. Auf diese Art bilden sich im Zuge des Trainings die Beziehungen der Tokens zueinander immer deutlicher heraus.
Am Ende dieses langen Prozesses ist in den Embeddings die Komplexität von sprachlichen Äußerungen nicht nur auf Wort- oder Satzebene, sondern auch auf Konzept- und Ideen-Ebene gespeichert. Es entwickelt sich eine 1000-dimensionale Landkarte (bei GPT-3.5 sind es 12.288 Dimensionen) der Sprache. In dieser Landkarte ist hinterlegt, wie sich „Rot“ zu „Vorhang“ verhält, „Liebe“ zu „Haus“ und „Zitronensäurezyklus“ zu „Salat“. Das Modell kennt diese Dinge nicht aus eigener Anschauung, aber es hat aus den Millionen Texten erfahren, in welche vielfältigen Verhältnisse wir diese Begriffe zueinander setzen.
Diese Landkarte wird auch als „latent space“, als latenter Raum bezeichnet. Im latenten Raum liegen semantisch ähnliche Wörter nahe beieinander und semantisch unähnliche sind weiter entfernt. Ein vereinfachtes Beispiel: Zieht man vom Embedding „König“ das Embedding „Mann“ ab und addiert das Embedding „Frau“, landet man im Latenten Raum beim Embedding „Königin“ (Mikolov et al. 2013).5
LLMs sind kompetent, auf dieser Landkarte zu navigieren. Gibt man z.B. GPT-3.5 einen Textanfang, dann ist das, als hätte man dem Modell einen Pfad auf dieser Landkarte vorgezeichnet und es am Endpunkt des Pfades abgesetzt mit der Aufgabe, ihn selbstständig weiterzugehen. Das ist eine anspruchsvolle Aufgabe, gibt es doch auf jeder der 12.288 Dimensionen Nähen und Fernen zu anderen Tokens (z.B. assoziative Nähen und Fernen, funktionale Nähen und Fernen, phonetische Nähen und Fernen etc.).
Dabei sind zwar alle Tokens des bereits zurückgelegten Weges mit in Betracht zu ziehen, doch der Aufmerksamkeitsmechanismus hat wichtige Wegmarken nochmal gesondert gekennzeichnet, um Orientierung zu geben. Wie ein Pfadfinder sucht GPT-3.5 nun nach möglichst ausgetretenen Pfaden, die mit dem Herkunftspfad und den Orientierungsmarken in Übereinstimmung zu bringen sind.
Eine interessante Besonderheit bei LLMs ist, dass man Einfluss nehmen kann, wie ausgetreten die Pfade sein sollen, die das Modell aussucht. Die einfachste Idee wäre, tatsächlich immer das wahrscheinlichste Wort zu nehmen und auszuspucken. Es hat sich jedoch gezeigt, dass die Texte dadurch oft sehr starr und wenig interessant werden und dass sie schnell dazu tendieren, sich zu wiederholen. Deswegen kann man über die „Temperatur“ die „Wildheit“ des Modells einstellen.
Temperatur ist ein Wert, der angibt wie oft das Modell nicht das wahrscheinlichste, sondern auch mal das zweit- oder drittwahrscheinlichste Wort als Vorhersagen verwenden soll. Bei einer Temperatur von 0,1 wird das Modell sehr konsistente, aber langweilige Texte produzieren, bei einer Temperatur von 0,9 kommt kaum mehr verständliches Gerede bei rum. Meist wird deswegen mit einer Temperatur um die 0,7 gearbeitet (Wolfram 2023).
Der Aufstieg der Transformer-Modelle
Seit 2012 haben sich viele unterschiedliche Architekturen für KNNs durchgesetzt. Multilayer Perceptrons (MLP), Convolutional Neural Networks (CNN) und Recurrent Neural Networks (RNN) waren vor den Transformermodellen die populärsten Architekturen. Sie sind heute überall zu finden. In Fotosoftware, Suchalgorithmen, oder auch in der Industrie in den unterschiedlichsten Anwendungen.
Der technologische Durchbruch, der die aktuell erfolgreichen generative KIs wie ChatGPT, aber auch Bildgeneratoren wie Midjourney und Stable Diffusion ermöglicht hat, wurde 2017 durch Forscher*innen bei Google in einem Paper mit dem Titel „Attention Is All You Need“ (Vaswani et al. 2017) beschrieben. In dem Aufsatz wird das sogenannte Transformer-Modell beschrieben. Das ist eine Architektur für KNN, die jeder versteckten Ebene (in diesem Fall heißt sie „Feed-Forward-Ebene“) eine sogenannte Aufmerksamkeits-Ebene zur Seite stellt (Nyandwi 2023). Die soll ihr helfen, den relevanten Kontext der aktuellen Aufgabe besser im Blick zu behalten, indem er den in den Embeddings zusätzlich vermerkt wird.
Aufmerksamkeit ist deswegen wichtig, weil z. B. beim Generieren des nächsten Tokens zwar der ganze Kontext (alles vorher Geschriebene) mit in Betracht gezogen werden muss, aber eben nicht alles gleich stark (Serrano 2023). Um den Satz „Die Schlüssel liegen dort, wo ich sie hingelegt habe.“ zu schreiben, muss das System z. B. beim Generieren des Wortes „sie“ wissen, dass es sich auf „Schlüssel“ bezieht. Das Wort Schlüssel ist in diesem Moment des Generierens von „sie“ also wichtiger als die anderen Worte des Satzes.
Die Aufmerksamkeits-Ebene assistiert der versteckten Ebene, indem sie den jeweiligen Kontext des zu bearbeitenden Tokens nach Relevanz sortiert und entsprechend gewichtet. Für jeden Token im Kontext-Fenster wird die Relevanz jedes anderen Tokens berechnet und diese in seinen Embeddings vermerkt. Das hilft nicht nur dabei, grammatikalische Konsistenz zu erhalten. Die Tokens (und damit die multidimensionalen Embeddings) durchwandern das ganze Netzwerk von Aufmerksamkeits- und Feed-Forward-Ebenen und werden von jeder einzelnen der Aufmerksamkeitsebenen mit neuen Kontexten angereichert, die als neue Dimensionen im jeweiligen Embedding vermerkt werden.
Heutige Modelle haben sehr viele von diesen Ebenen, bei GPT-3.5 sind es über 90. In den tieferliegenden Ebenen, dort wo abstraktere Aspekte prozessiert werden, hilft der Attention-Mechanismus dem Modell unter anderem narrative oder konzeptionelle Kohärenz eines Textes zu gewährleisten (Lee/Trott 2023).
Wenn man z. B. einen Text mit der Hochzeit von Alice und Bob anfängt, „versteht“ das System, dass diese Hochzeit und ihre Protagonisten wichtig für die Fortführung des Textes bleiben und schreibt ihn fort, ohne dabei den thematischen Fokus zu verlieren. Oder wenn man das Modell bittet, eine komplexe Denkaufgabe zu lösen, hilft der Attention-Mechanismus, sich auf die wesentlichen Bestandteile der Antwort zu konzentrieren.
Es stellt sich heraus, dass fokussierte Aufmerksamkeit auf jeder Abstraktionsebene auf unterschiedliche Weise hilfreich ist. Am Ende, wenn das System die Entscheidung darüber trifft, welches nächste Wort nun ausgegeben wird, sind alle bisherigen Tokens des Kontext-Fensters mit abertausenden zusätzlichen kontextbezogenen Dimensionen angereichert, die mit in die Berechnung einbezogen werden.
Die Transformer-Architektur ermöglicht es dem System zudem, die Aufmerksamkeits-Gewichtungen parallel für viele Worte gleichzeitig zu berechnen. Das spart Zeit und erklärt, warum Grafikprozessoren (GPUs) mit vielen Prozessorkernen eine wichtige Ressource für die Entwicklung von aktuellen LLMs darstellen.
Eine weitere Eigenschaft von Transformer-Modellen ist, dass sie nach dem Training noch verfeinert werden können. Nach dem initialen Training erhält man ein sogenanntes „pre-trained model“ oder auch „foundational model“ genannt. Die durch das Pre-Training erworbene Kompetenz im Interpretieren von Sprache kann dann für die Feinabstimmung des Systems genutzt werden. So kann es durch ein sogenanntes „reinforcement learning by human feedback“ auf bestimmte Aufgaben optimiert werden, beispielsweise für Übersetzungsaufgaben, Textanalyse, Recherche oder den Einsatz als Chatbot wie ChatGPT.
Bei OpenAI z. B. geschieht das Reinforcement Learning in zwei Schritten: speziell geschulte Leute werden beschäftigt, um Beispiel-Prompts und dazugehörige „gute“ Antworten zu erstellen, mit denen das System weitertrainiert wird. Dabei werden vergleichsweise wenig Trainingsdaten verwendet, diese sind aber qualitativ hochwertig und werden im Training stärker gewichtet. In einem zweiten Schritt lässt man das Modell nach diesen Vorbildern selbst mehrere Antworten auf einen Prompt generieren und lässt Menschen die beste der Antworten auswählen (Karpathy 2023).
Josh Dzieza bringt die Rolle des Fine-tuning in einem Artikel für die The Verge auf den Punkt: „Anders ausgedrückt, scheint ChatGPT so menschlich zu sein, weil es von einer KI trainiert wurde, die Menschen nachahmte, die wiederum eine KI bewerteten, die Menschen imitierte, die so taten, als wären sie eine bessere Version der KI, die auf menschlichen Texten trainiert wurde.“ (Dzieza 2023).
Literatur
- Box, George E. P. (1979): Robustness in the strategy of scientific model building. In: Launer, Robert L. / Wilkinson, Graham N. (Hrsg.): Robustness in Statistics, Cambridge, Mass.: Academic Press, S. 201–236. https://doi.org/10.1016/b978-0-12-438150-6.50018-2 (Abruf am 4.9.2023).
- Chiang, Ted (2023): ChatGPT Is a Blurry JPEG of the Web. In: The New Yorker, 9.2.2023. www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web (Abruf am 18.8.2023).
- Dertat, Arden (2017): Applied Deep Learning – Part 1: Artificial Neural Networks. In: Towards Data Science, 8.8.2017. https://towardsdatascience.com/applied-deep-learning-part-1-artificial-neural-networks-d7834f67a4f6 (Abruf am 18.8.2023).
- Dzieza, Josh (2023): AI Is a Lot of Work. In: The Verge, 20.6.2023. www.theverge.com/features/23764584/ai-artificial-intelligence-data-notation-labor-scale-surge-remotasks-openai-chatbots (Abruf am 18.8.2023).
- Karpathy, Andrej (2023): State of GPT. Microsoft Build. https://build.microsoft.com/en-US/sessions/db3f4859-cd30-4445-a0cd-553c3304f8e2 (Abruf am 18.8.2023).
- Loiseau, Jean-Christophe B. (2019): Rosenblatt’s perceptron, the first modern neural network. A quick introduction to deep learning for beginners. In: Towards Data Science, 11.3.2019. https://towardsdatascience.com/rosenblatts-perceptron-the-very-first-neural-network-37a3ec09038a (Abruf am 18.8.2023).
- Mahowald, Kyle / Ivanova, Anna A. / Blank, Idan A. / Kanwisher, Nancy / Tenenbaum, Joshua B. / Fedorenko, Evelina (2023): Dissociating language and thought in large language models: a cognitive perspective. https://arxiv.org/pdf/2301.06627 (Abruf am 18.8.2023).
- Mayo, Benjamin (2023): Apple says it has fixed iPhone autocorrect with iOS 17. In: 9TO5Mac, 5.6.2023. https://9to5mac.com/2023/06/05/ios-17-iphone-autocorrect/ (Abruf am 18.8.2023).
- Mikolov, Tomas / Sutskever, Ilya / Chen, Kai / Corrado, Greg / Dean, Jeffrey (2013): Distributed Representations of Words and Phrases and their Compositionality. In: Advances in Neural Information Processing Systems 26, S. 3111–3119.
- Nagyfi, Richard (2018): The differences between Artificial and Biological Neural Networks. In: Towards Data Science, 4.9.2018. https://towardsdatascience.com/the-differences-between-artificial-and-biological-neural-networks-a8b46db828b7 (Abruf am 18.8.2023).
- Natale, Simone (2021): Deceitful Media. Artificial Intelligence and Social Life after the Turing Test, Oxford: Oxford University Press.
- Nyandwi, Jean (2023): The Transformer Blueprint. A Holistic Guide to the Transformer Neural Network Architecture. In: Deep Learning Revision, 29.7.2023. https://deeprevision.github.io/posts/001- transformer/ (Abruf am 18.8.2023).
- Saeed, Waddah / Omlin, Christian (2023): Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. In: Knowledge-Based Systems 263. DOI: 10.1016/j.knosys.2023.110273. (Abruf am 18.8.2023).
- Schaul, Kevin / Chen, Szu Yu / Tiku, Nitasha (2023): Inside the secret list of websites that make AI like ChatGPT sound smart. In: The Washington Post, 19.4.2023. www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/ (Abruf am 18.8.2023).
- Vaswani, Ashish / Shazeer, Noam / Parmar, Niki / Uszkoreit, Jakob / Jones, Llion / Gomez, Aidan N. / Kaiser, Lukasz / Polosukhin, Illia (2017): Attention Is All You Need. https://arxiv.org/abs/1706.03762 (Abruf am 18.8.2023).
- Wolfram, Stephen (2023): What Is ChatGPT Doing … and Why Does It Work? https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/ (Abruf am 18.8.2023).
Fußnoten
- Dieser Unterschied wird vielleicht nicht mehr lange existieren. Apple hat bereits für sein aktuelles Smartphone-Betriebssystem angekündigt, die Wortvorschläge und Autokorrekturen in Textnachrichten tatsächlich mithilfe eines GPT zu generieren (Mayo 2023). ↩
- Zu den tatsächlichen Unterschieden von künstlichen und natürlichen Neuronen siehe Nagyfi 2018. ↩
- Das ist, wie gesagt, ein vereinfachtes Beispiel zur Veranschaulichung der ungefähren Verarbeitungsmechanik. In Wirklichkeit ist sie wesentlich komplexer, und Wissen- schaftler*innen haben große Schwierigkeiten, bestimmte Informationsverarbeitungsschritte einem Neuron oder eine Ebene zuzuordnen. Tatsächlich ist die Verarbeitungsmechanik ein eigenes Forschungsfeld (vgl. Saeed/Omlin 2023). ↩
- Um einen Eindruck zu bekommen, wie diese Trainingsdaten aufgebaut sind, hat die Washington Post ein populäres Trainingsdaten-Set in einer Infografik aufbereitet (Schaul/Chen/Tiku 2023). ↩
- Das Beispiel ist aus dem Vektorraum eines Sprachmodells aus dem Jahr 2013, also vor der Erfindung der Transformer-Modelle, es sollte aber auch für aktuelle Systeme eine ungefähre Gültigkeit haben. ↩





Pingback: Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft – Hans-Böckler-Stiftung | H I E R
Pingback: Mehr als heiße Luft – Raum und Freude
Pingback: #weeklyreview 39/23 | Falko Zurell