Large language models like ChatGPT can help us to better understand the connection between language and thought. This is an opportunity for a new enlightenment.
Since its invention in the course of the Dartmouth Workshop of 1956, the term “artificial intelligence” has been the subject of a battle of interpretation that its users ultimately always lose. Artificial intelligence research is to intelligence what negative theology is to God. It constantly finds out what intelligence is not. We learned early on that mental arithmetic of all things is the simplest problem to solve digitally, that even sorting apparently doesn’t require much intelligence, that not even playing chess or Go is a definitive proof of intelligence, that cats can be distinguished from dogs or even driving a car apparently can be done without a great deal of intelligence.
In the face of the current hype surrounding generative artificial intelligence – image generators like Midjourney or large language models (LLMs) like ChatGPT – the question arises again: is the astonishingly correct use of words and images by machines “intelligent”?
One faction believes to recognize a “spark of general intelligence” in the large frontier models such as GPT-4, Claude 3, Gemini 1.5, the other faction believes that we are only dealing with “stochastic parrots”, a kind of autocorrection on speed. So the dispute is about “cognition” and whether the “intelligence” is in the machine. It seems more sensible to me to first clarify the relationship between language and thought.
Derrida and the Linguistic Turn
In the second half of the 20th century, the “linguistic turn” occurred in the Humanities. Roughly speaking, the assumption that the possibility of thought is linked to the use of language became widespread, a thesis that is still discussed today in cognitive science as the Sapir–Whorf hypothesis. According to this thesis, we have no direct access to the world because our perception is already symbolically mediated. The cultural studies theories that emerged at the time, in particular “structuralism”, thus sought to make the hidden structural influences of language on thought visible.
Jaques Derrida, as a representative of “post-structuralism”, went one step further and showed that even the signs themselves have no direct reference to the world. Language is not a gateway to reality, but a free-floating system of symbolic referentiality. Derrida’s texts are difficult to understand, but to illustrate his point for our purposes, it is enough to pick up a dictionary. If you look up a word, you will only ever be referred to other words, and if you look them up, you will only find more words, etc. According to Derrida’s thinking, signs only ever refer to other signs, rather than to some kind of “reality”.
The mere fact that LLMs can spit out semantically correct sentences based only on linguistic utterances, without any reference to reality, seems to fundamentally confirm this thesis. However, the closer you look at the technology of AI, the more you get the impression that large language models are operationalized post-structuralism.
Meaning in latent space
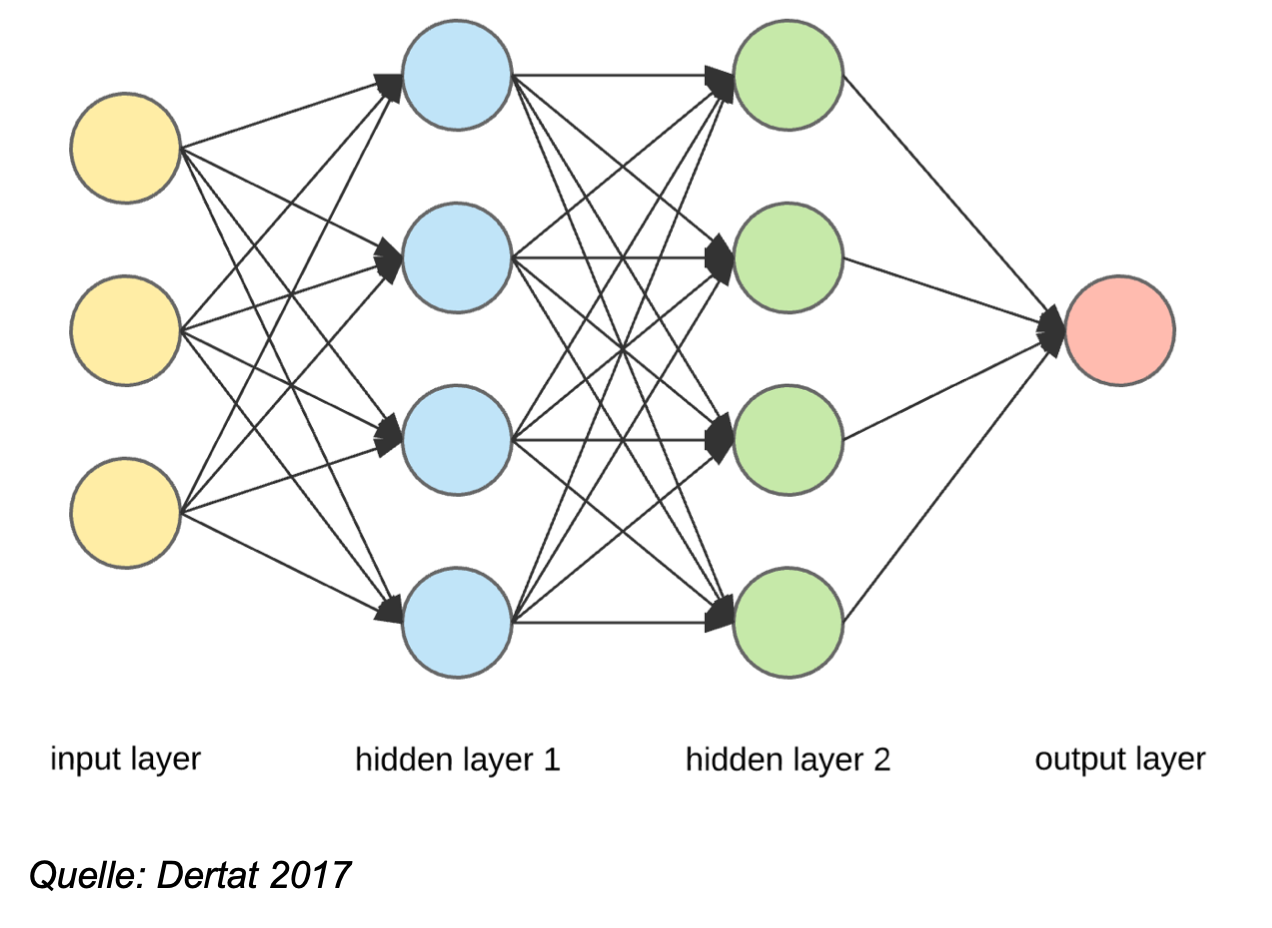
Large Language Models always output the next word using probabilistic calculations. In contrast to traditional autocorrect, the LLM not only includes the previous word in the probability calculation, but all previous words. And these previous words are not simply included in the calculation as a combination of letters, but as so-called “embeddings”.
Words or parts of words are called “embeddings” if they are put into a relationship to all other words within a „vector space“. This vector space in LLMs is also called “latent space” and can be imagined as a thousand-dimensional network of terms and all their occuring relationships. The latent space is the result of the LLM’s basic training, in which all the different ways in which terms can be related to each other were stored by statistically measuring through millions of texts.
Since all the connections are precisely weighted, the expanses of this highly complex network cloud contain both close and distant relationships of all kinds: functional, syntactical, legal, foreign-language, ethical, political, aesthetic, etymological and, of course, numerous associative constellations. The Latent Space is a rugged, multi-dimensional landscape of our language.
If we zoom into this network, we find, for example, the word “king”, which has a specific location in this network that results from the connections to thousands of other words. One of these vectors, with which “king” is associated, is the vector “man”. If you subtract “man” from the “king” vector and add the “woman” vector, you end up in the latent space with the word “queen”.
On closer inspection, the latent space turns out to be a more complex variant of Derrida’s dictionary. And just as the dictionary promises us orientation in terms, the latent space of the LLM serves as a map of language. And just as the road network maps out all possibilities for getting from A to B, in Latent-Space all existing and possible sentences, paragraphs, essays or books are laid out as latent routes.
For Derrida, meaning is an effect of moving within this network. It manifests itself in reading, speaking, writing, and thinking as a concrete route from one point in the network to another. Reading, speaking, writing, and thinking are thus navigational maneuvers within this bizarre landscape, in which not all paths are equally probable. Those who want to be understood follow the well-trodden paths.
Technically, you can imagine the process like this: when reading the prompt, the model follows the predefined path (the prompt) within the latent space, word for word, enriching what it reads with all kinds of “embedded”, i.e. multi-dimensional contextual semantics. At the end of the prompt, it then turns its position in the network into the starting point for an independent navigation, the aim of which is to extend the given path to its conclusion in a “plausible way”.
To put some distance between LLMs and humans again, it helps to imagine the latent space of LLMs as a limited and reduced dimensional “impression” of human semantics. Just as the footprint does not represent the whole foot, the latent space also lacks a number of dimensions that we humans include in our references when reading, speaking, writing, and thinking. Emotional, social, material, and even cognitive vectors of consciousness are simply not available to the LLM. You could say that machine semantics is broad and flat, while human semantics is deep and narrow.
Semantics all the way down
But what does this tell us about the machine’s ability to think? It means, first of all, that part of what we perceive as intelligent in humans, and more recently in machines, lies outside the brain and the data center. A good deal of human intelligence is encoded in language, in shared semantics. And this is not primarily a technical or cognitive discovery, but rather one that impacts cultural studies.
This becomes clear if, with Niklas Luhmann, we understand “semantics” as the “stock of meaning of a society”. It is not just about language and writing, but about all conceivable forms of meaning. Although image and audiovisual semantics are also made operational by the image, audio and video generators, we have to imagine the human semantic space as much more comprehensive. From “indicating left turn” to history, from the middle finger to the scientific experiment, from dark metal to the spring collection. The way I move my hand is semantics, “zeitgeist” is a very specific set of semantics, a single look can overflow with semantics, every couple develops an intimate private semantics, even grammar is a semantics and what a dog experiences when it walks through the forest, surrounded by millions of exciting smells, is a thicket of semantics that are plausible to him.
When Heidegger speaks of language as “the house of being”, he means our inclusion in this network of semantics. Each of us inhabits only a small part of this overall structure, and this part essentially determines what we are able to think at all. We are born into our semantic section and have been working ever since to expand it, looking for connections, learning words, works and gestures, and some rooms we have not entered for quite some time.
From world model to program
In a sense, the post-structuralist view thus seconds the notion of the stochastic parrot, albeit with the addition that human thought also consists to a large extent of stochastic semantics routing.
The opposing side always points to the “reasoning” abilities of models such as GPT-4 or Claude 3, and indeed it is astonishing how they can not only produce semantically correct sentences like “The ice melts in the sun,” but also perform surprisingly well in exam papers and other benchmarks. LLMs show themselves to be surprisingly empathetic and creative and can apply theories and methods correctly in a wide variety of contexts. The developers of the systems beliefe that the LLMs have developed a “world model” in the course of their training that allows them to use these often imperfect “reasoning” abilities.
We now have a simpler explanation: no one doubts that language is a system of rules at the orthographic and grammatical level, and LLM shows that this also applies to meaning and to all concepts, logics, methods and theories. Whether grammar, algebra, multistakeholder analysis or interpreting poetry: these are all rule-based thought templates, patterns of correct expression or factories of probable sentences.
Francois Chollet, an AI researcher and Google employee, calls these macro-semantic rule complexes “programs”. Of course not in the literal sense of machine-readable code, but rather as macro-semantic paths that have sedimented in the learning process and were generalized for applicability. Just as plausible words are strung together when formulating sentences, statements are arranged along predetermined paths when macro-semantic programs are applied. By applying them, LLMs work their way through the corresponding context and perform their rule-based operations on it, in order to generate an expected output.
We humans have also practiced many of these macro-semantic programs, sometimes consciously, but more often unconsciously. And because they also determine our view of the world, I see an emancipatory mission resulting from the invention of the LLM. This archive is incredibly deep and possibly contains the programs for all our thinking. Extracting, examining and debating these social semantics of ours, offers the possibility of a new enlightenment.
Large Language Models wie ChatGPT können uns helfen, den Zusammenhang zwischen Sprache und Denken besser zu verstehen. Darin liegt die Chance für eine neue Aufklärung.
/******
Eine leicht gekürzte Version dieses Textes erschien im Magazin „Human“ 3/24. Das Heft kann man hier bestellten. [English Version]
******/
Seit seiner Erfindung im Zuge des Dartmouth Workshop von 1956 rankt um den Begriff der „Künstliche Intelligenz“ ein Deutungskampf, der für seine Verwender letztendlich immer verloren geht. Künstliche Intelligenz-Forschung verhält sich zu Intelligenz, wie negative Theologie zu Gott. Sie findet ständig heraus, was Intelligenz nicht ist. Früh lernten wir, dass ausgerechnet Kopfrechnen das einfachste digital zu lösende Problem ist, dass auch Sortieren anscheinend nicht viel Intelligenz benötigt, dass nicht mal Schach- oder Go-Spielen ein endgültiger Ausweis von Intelligenz ist, dass auch Katzen von Hunden zu unterscheiden oder sogar Autofahren offenbar ohne besonders viel Intelligenz zu bewerkstelligen ist.
Angesichts des aktuellen Hypes um generative Künstliche Intelligenz – Bildgeneratoren wie Midjourney oder Large Language Modells (LLMs) wie ChatGPT – ist die Frage wieder in aller Munde: ist die erstaunlich korrekte Verwendung von Wörtern und Bildern durch Maschinen „intelligent“?
Die eine Fraktion glaubt, einen „funken genereller Intelligenz“ in den großen Frontier-Modellen wie GPT-4, Claude 3, Gemini 1.5 zu erkennen, die Gegenseite glaubt, dass wir es nur mit „stochastischen Papageien“ zu tun haben, einer Art Autokorrektur auf Speed. Es wird also um „Kognition“ gestritten und darum, ob die „Intelligenz“ in der Maschine steckt. Mir scheint es sinnvoller, erstmal zu klären, wie Sprache und Denken zusammenhängen.
Derrida und der Linguistic Turn
In der zweiten Hälfte des 20. Jahrhunderts ereignete sich in den Kulturwissenschaften der „Linguistic Turn“. Ganz grob gesprochen verbreitete sich die Annahme, dass die Möglichkeit des Denkens an die Verwendung von Sprache gekoppelt sei, eine These die noch heute in der Kognitionswissenschaft als Sapir–Whorf-Hypothese diskutiert wird. Der These zufolge haben wir keinen direkten Zugriff auf die Welt, weil schon unsere Wahrnehmung symbolisch vermittelt ist. Die damals entstandenen kulturwissenschaftlichen Theorien, insbesondere der „Strukturalismus“, versuchte folglich die verdeckten Struktureinflüsse der Sprache auf das Denken sichtbar zu machen.
Jaques Derrida ging als Vertreter des „Poststrukturalismus“ noch einen Schritt weiter und zeigte, dass auch die Zeichen selbst keinen direkten Bezug auf die Welt haben. Sprache sei kein Gateway zur Realität, sondern ein freiflottierendes System der Referenzialität der Zeichen. Derridas Texte sind schwer verständlich, aber um seinen Punkt für unsere Zwecke zu veranschaulichen, reicht es, ein Wörterbuch zur Hand zu nehmen. Schlägt man darin ein Wort nach, wird man immer nur auf andere Worte verwiesen und schaut man diese nach, stößt man ebenfalls wieder nur auf Worte, usw. Dem Denken Derridas zufolge verweisen Zeichen immer nur auf andere Zeichen, statt auf irgendeine „Realität“.
Allein die Tatsache, dass LLMs, so ganz ohne jeden Realitätsbezug und nur durch die Auswertung sprachlicher Äußerungen semantisch korrekte Sätze ausspucken können, wirkt wie eine grundsätzliche Bestätigung dieser These. Doch je näher man sich mit der Technik der KI beschäftigt, desto mehr verdichtet sich der Eindruck, dass Large Language Models operationalisierter Poststrukturalismus sind.
Bedeutung im Latent-Space
Large Language Models geben immer das jeweils nächste Wort mittels Wahrscheinlichkeitsrechnung aus. In die Berechnung der Wahrscheinlichkeit bezieht die LLM im Gegensatz zur klassischen Autokorrektur nicht nur das vorherige Wort, sondern alle Vorherigen Worte mit ein. Und diese vorherigen Worte wiederum gehen nicht einfach als Buchstabenkombination mit in die Berechnung ein, sondern als sogenannte „Embeddings“.
„Embeddings“ werden Worte oder Wortbestandteile genannt, wenn sie mit allen anderen Worten in einem Vektorraum auf vielfältige Weise in Bezug gesetzt werden. Dieser Vektorraum wird bei LLMs auch „Latent-Space“ genannt und man kann sich ihn als tausenddimensionales Netzwerk von Begriffen und ihren möglichen Beziehungen vorstellen. Der Latent-Space ist das Resultat des Basistrainings der LLM, bei dem durch die statistische Durchmessung von Millionen von Texten all die unterschiedlichen Möglichkeiten abgespeichert wurden, in denen Begriffe zueinander in Beziehung stehen können.
Da alle Verbindungen exakt gewichtet sind, finden sich in den Weiten dieser hochkomplexen Netzwerkwolke Nähen und Fernen, darunter funktionale, syntaktische, rechtliche, fremdsprachige, ethische, politische, ästhetische, etymologische und natürlich etliche assoziative Konstellationen. Der Latent-Space ist eine zerklüftete, vieldimensionale Landschaft der Sprache.
Wenn wir in dieses Netzwerk hineinzoomen, dann finden wir dort z.B. das Wort „König“, das einen konkreten Ort in diesem Netzwerk hat, der sich aus den Verbindungen zu tausenden anderen Worten ergibt. Einer dieser Vektoren, mit dem „König“ im Zusammenhang steht, ist der Vektor „Mann“. Zieht man „Mann“ vom Vektor „König“ ab und addiert den Vektor für „Frau“ hinzu, dann landet man im Latent-Space beim Wort „Königin“.
Bei genauerer Betrachtung haben wir es beim Latent-Space also nur mit einer komplexeren Variante von Derridas Wörterbuch zu tun. Und so wie uns das Wörterbuch Orientierung in den Begriffen verspricht, so dient auch der Latent-Space der LLM als Landkarte der Sprache. So wie das Straßennetz alle Möglichkeiten des von A nach B-kommens vorzeichnet, so sind im Latent-Space alle existierenden und möglichen Sätze, Absätze, Aufsätze oder Bücher als latente Routen angelegt.
Bedeutung ist bei Derrida ein Effekt des sich Bewegens in diesem Netzwerk. Sie manifestiert sich im Lesen, Sprechen, Schreiben, Denken als konkrete Route von einem Punkt im Netzwerk zu einem anderen. Lesen, Sprechen, Schreiben, Denken sind also Navigationsmanöver innerhalb dieser bizarren Landschaft, in der nicht alle Wege gleichwahrscheinlich sind. Wer verstanden werden will, folgt den ausgetretenen Pfaden.
Technisch kann man sich das so vorstellen: Beim Einlesen des Prompts läuft das Modell den von uns vorgezeichneten Pfad im Latent-Space Wort für Wort ab und reichert dabei das Gelesene mit allerlei „embeddeten“, d.h. vieldimensional kontextuellen Semantiken an. Am Ende des Prompts macht es seine Position im Netzwerk dann zum Ausgangspunkt einer selbstständigen Navigation, bei der es darum geht, den vorgegebenen Pfad auf „plausible Art“ zu Ende zu führen.
Um wieder etwas Abstand zwischen LLMs und Menschen zu bringen, hilft es, sich den Latent-Space der LLMs als einen begrenzten und unterdimensionierten „Abdruck“ menschlicher Semantiken vorzustellen. So wie der Fußabdruck nicht den ganzen Fuß abbildet, fehlen auch im Latent-Space etliche Dimensionen, die wir Menschen in unseren Bezugnahmen beim Lesen, Sprechen, Schreiben, Denken einbeziehen. Emotionale, soziale, materielle und auch die kognitiven Vektoren des Bewusstseins stehen der LLM schlicht nicht zur Verfügung. Man könnte sagen, die maschinelle Semantik ist breit und flach, die menschliche dagegen tief und eng.
Semantiken all the Way down
Doch was sagt das jetzt über die Denkfähigkeit der Maschine aus? Es bedeutet erstmal, dass ein Teil dessen, was wir bei Menschen, wie neuerlich bei Maschinen als intelligent wahrnehmen, außerhalb der Gehirne und Rechenzentren liegt. Ein Gutteil der menschlichen Intelligenz ist in der Sprache codiert, in den geteilten Semantiken. Und das ist nicht in erster Linie eine technische oder kognitionswissenschaftliche, sondern eine kulturwissenschaftliche Entdeckung.
Das wird klar, wenn man „Semantik“ mit Niklas Luhmann als den “Bedeutungsvorrat der Gesellschaft“ versteht. Es geht eben nicht nur um Sprache und Schrift, sondern um alle denkbaren Weisen des Bedeutens. Zwar werden mit den Bild-, Audio- und Video-Generatoren parallel auch die bildlichen und audiovisuellen Semantiken operationalisierbar gemacht, doch man muss sich den menschlichen, semantischen Raum noch viel umfassender vorstellen. Vom „Links Blinken“ bis zur Geschichtswissenschaft, vom Stinkefinger zum experimentellen Versuchsaufbau, von Dark Metall bis zur Frühjahrskollektion. Die Art meine Hand zu bewegen ist Semantik, „Zeitgeist“ ist ein ganz bestimmtes Set an Semantiken, ein einziger Blick kann vor Semantik überquellen, jedes Liebespaar entwickelt eine intime Privatsemantik, selbst Grammatik ist eine Semantik und das, was ein Hund erfährt, wenn er durch den Wald läuft, umgeben von Millionen spannenden Gerüchen, ist ein Dickicht aus für ihn plausiblen Semantiken.
Wenn Heidegger von der Sprache als „das Haus des Seins“ spricht, dann meint er unsere Eingeschlossenheit in dieses Netzwerk aus Semantiken. Jeder von uns bewohnt nur einen kleinen Ausschnitt dieses Gesamtgefüges und der bestimmt wesentlich mit, was wir überhaupt in der Lage sind, zu denken. Wir sind in unseren Semantik-Ausschnitt hineingeboren und arbeiten seitdem daran, ihn auszudehnen, suchen Anschlüsse, lernen Worte, Werke und Gesten und manche Zimmer haben wir schon länger nicht mehr betreten.
Vom World Modell zum Programm
In gewisser Weise gibt die poststrukturalistische Betrachtung also dem Bild des Stochastischen Papageien statt, allerdings mit der Ergänzung, dass auch das menschliche Denken zu einem Gutteil aus stochastischer Regelbefolgung besteht.
Die Gegenseite verweist dann immer auf die „Reasoning“-Fähigkeiten von Modellen wie GPT-4 oder Claude 3 und tatsächlich ist es erstaunlich, wie sie nicht nur semantisch korrekte Sätze, wie „Das Eis schmilzt in der Sonne“ produzieren können, sondern auch in Examensklausuren und anderen Benchmarks überraschend gut abschneiden. LLMs zeigen sich erstaunlich empathisch und kreativ und können Theorien und Methoden in unterschiedlichsten Kontexten richtig anwenden. Von den Entwicklern der Systeme heißt es, die LLMs hätten sich im Zuge ihres Trainings ein „World Modell“ erarbeitet, das ihnen diese noch oft unperfekten „Reasoning“-Fähigkeiten erlaubt.
Wir haben jetzt eine einfachere Erklärung: Dass Sprache ein Regelsystem ist, zweifelt auf der orthographischen und grammatikalischen Ebene niemand an und die LLM zeigt eben, dass das auch für Bedeutungen und auch für alle Konzepte, Logiken, Methoden und Theorien gilt. Egal ob Grammatik, Algebra, Multistakeholder-Analyse oder Gedichtinterpretation: Alles das sind regelgeleitete Denkschablonen, Strukturen des Richtigen Sagens oder Fabriken wahrscheinlicher Sätze.
Der KI-Forscher und Google-Mitarbeiter, Francois Chollet nennt diese makrosemantischen Regelkomplexe „Programme“. Natürlich nicht im wortwörtlichen Sinne wie maschinenlesbarer Code, sondern Programme vielmehr als im Lernprozess hängengebliebene und zur Anwendwendbarkeit abstrahiert markosemantische Pfade. So wie beim Formulieren von Sätzen plausible Worte aneinandergereiht werden, werden bei der Anwendung solcher makrosemantischen Programme Aussagen entlang vorgezeichneter Pfade arrangiert. Wenn die LLM sie anwendet, arbeitet sie sich entlang ihrer regelgeleiteten Operationen durch den entsprechenden semantischen Kontext und ist so in der Lage automatisiert einen erwartungsgemäßen Output zu generieren.
Auch wir Menschen haben etliche dieser makrosemantischen Operationen eingeübt, manchmal bewusst, viel öfter unbewusst. Und weil sie auch unseren Blick auf die Welt bestimmen, sehe ich in der Erfindung der LLM einen emanzipatorischen Auftrag. Dieses Archiv ist unglaublich tief und darin sind womöglich alle Programme codiert, die unser Denken leiten. Im Extrahieren, Untersuchen und zur Debatte stellen dieser unserer gesellschaftlichen Semantiken steckt die Möglichkeit einer neuen Aufklärung.
Vom Supplychain-Kapitalismus zum Plattform-Merkantilismus
/******
Für den Tagungsband „Materialität des Digitalen“ habe ich meinen Vortrag über Materialität und Austauschbarkeit verschriftlicht. Er bildet – zusammen mit „KI ist ein Coup“ – die Vorstudie eines größeren Projektes zur politischen Ökonomie der Abhängigkeiten, zu dem es hier noch einiges zu lesen geben wird.
******/
Einleitung
In einer 2015 viral gegangenen Vortragsfolie schreibt Tom Goodwin:
»Uber, the world’s largest taxi company, owns no vehicles. Facebook, the world’s most popular media owner, creates no content. Alibaba, the most valuable retailer, has no inventory. And Airbnb, the world’s largest accommodation provider, owns no real estate« .
(Goodwin via McAfee/Brynjolfsson 2017: 8)
In der beschriebenen Welt schweben die Plattformunternehmen über der Welt des Materiellen und dirigieren Autos, Inventar und Immobilien durch algorithmische Suggestion, wie der Zauberlehrling Besen und Eimer. Das Digitale hat den Kapitalismus ohne Frage ordentlich umgestaltet. Und im Zentrum steht dabei eine Abkehr vom Materiellen. Dieser Befund hat jedoch zwei Probleme:
Das Materielle, und darauf will ja gerade auch dieser Band aufmerksam machen, ist weiterhin relevant. Wir müssen heute sogar viel dringender als je über materiellen Ressourcen- und Energieverbrauch sprechen, den auch die digitale Welt in einem erstaunlichen Maß verursacht. Das Materielle ist nicht verschwunden, aber seine Rolle innerhalb der wirtschaftlichen Machtverhältnisse hat sich stark gewandelt. Zwischen der offensichtlichen Relevanz des Materiellen und seiner zunehmend marginalisierten Rolle innerhalb des Wirtschaftsgefüges klafft eine erklärungsbedürftige Lücke.
Diese Wandlung der Rolle des Materiellen setzt lange vor der Popularisierung des Internets und dem Siegeszug der Digitalisierung ein. In ihrem Buch Capital without Capital beschreiben Jonathan Haskell und Stian Westlake die Dematerialisierung des Kapitalismus als einen seit Jahrzehnten anhaltenden Trend, der mittlerweile dazu geführt hat, dass zumindest in den meisten westlichen Ökonomien die immateriellen die materiellen Werte längst überflügelt haben (Haskel/Westlake 2018). Digitale Plattformunternehmen spielen dabei zwar durchaus eine Rolle, jedoch nicht einmal die Hauptrolle. Der Trend zur Dematerialisierung ist weder auf die Digitalwirtschaft beschränkt, noch hat er dort angefangen.
Hier ein Auszug aus dem Bestseller No Logo von Naomi Klein (1999):
»The astronomical growth in the wealth and cultural influence of multinational corporations over the last fifteen years can arguably be traced back to a single, seemingly innocuous idea developed by management theorists in the mid-1980s: that successful corporations must primarily produce brands, as opposed to products«
(Klein 1999: 25)
Klein hatte schon um die Jahrtausendwende die Alarmglocken geläutet, dass sich der Kapitalismus aus der Welt der Dinge – also der Maschinen, der Arbeit, der Produkte – verabschiedet. Klein konzentriert ihre Analyse auf die Rolle des »Brandings«. Sogenannte »Superbrands« wie Nike oder Disney, so Klein, halten sich nicht mehr mit der Produktion von Waren auf, sondern sind praktisch reine Marketingfirmen ihrer selbst geworden, während die tatsächliche Produktion der Güter outgesourced wird.
Ich möchte deswegen die Gelegenheit nutzen, etwas weiter auszuholen und die Frage von Materialität und Immaterialität von der der Bits und Bytes lösen, um einen breiteren Begriff des Immateriellen, oder besser: des Dematerialisierten, zu entfalten. Mit dem Supply-Chain-Kapitalismus hat bereits im letzten Jahrhundert eine tiefgreifende Transformation des Kapitalismus eingesetzt, die dem Immateriellen gegenüber dem Materiellen den Vorzug gibt und das im aktuellen Plattformparadigma lediglich seinen derzeitigen Höhepunkt gefunden hat. Doch was steckt hinter dieser Transformation? Warum verlor das Materielle in den letzten Jahrzehnten an ökonomischer Bedeutung? Und wie verhalten sich die beiden Formen der Dematerialisierung – einerseits der Supplychains, andererseits der Plattformen – zueinander? Gibt es soetwas wie ein Bewegungsgesetz der Dematerialisierung?
Die Schwerelosigkeit der Marke
Naomi Klein erzählt die Geschichte der Dematerialisierung als Konsequenz eines Kapitalismus, der seine Nachfrage übertrumpft hat. Die Massenproduktion von Gütern war bis in die 1970er Jahre der Grundstein des wachsenden Wohlstands in der westlichen Welt. Seit den 1970er Jahren geriet die amerikanische Wirtschaft allerdings in eine Absatzkrise. Es wurde schlicht mehr produziert, als nachgefragt wurde. Um diese Nachfragesättigung zu überwinden, wurden immer mehr Geld und Ressourcen in Werbung und Marketing gesteckt; ein Wirtschaftszweig der dementsprechend einen wachsenden Anteil in der Ökonomie einnahm.
»Ever since mass production created the need for branding in the first place, its role has slowly been expanding in importance until, more than a century and a half after the Industrial Revolution, it occurred to these companies that maybe branding could replace production entirely«
(Klein 1999: 205).
Klein ist dabei sehr bewusst, dass die Immaterialität dieser Art des Wirtschaftens eine vorgetäuschte ist. Sie schreibt:
»Despite the conceptual brilliance of the ›brands, not products‹ strategy, production has a pesky way of never quite being transcended entirely: somebody has to get down and dirty and make the products the global brands will hang their meaning on«
(Klein 1999: 210)
Sie nimmt uns sodann mit auf eine Reise in die Länder des globalen Südens, wo sie die Fabriken der Zulieferbetriebe besichtigt hat, die Nike-Schuhe und Mickey Mouse-Puppen herstellen. Sie hat mit Arbeiter*innen gesprochen, die in sogenannten »Sonderwirtschaftszonen« noch weniger Rechte haben und noch skrupelloser ausgebeutet werden, als es in diesen Ländern sowieso schon üblich ist. Produkte in den Sonderwirtschaftszonen produzieren zu lassen ist natürlich billiger, weil die Arbeitskosten viel niedriger als in westlichen Industrienationen sind. Aber ein weiterer attraktiver Aspekt für diese Firmen ist, dass sich Marken nicht mit den Subunternehmern assoziieren lassen müssen. Klein erzählt die Geschichte des Disney-Unternehmenssprechers Ken Green, der auf die kritische Frage nach den unmenschlichen Arbeitsbedingungen in den Fabriken in Haiti entgegnete »We don’t employ anyone in Haiti« (Klein 1999: 205).
Klein hat durchaus recht, wenn sie sagt, dass die Konzentration auf Marketing und Branding einer der Treiber der Abkehr vom Materiellen ist. Das ist aber nur die halbe Wahrheit. Denn das, was diese Firmen überhaupt befähigt, Zulieferer in anderen Regionen der Welt zu beauftragen, basiert auf einer zweiten großen, wenn nicht viel grundlegenderen Verwandlung des Kapitalismus: die strukturelle Transformation großer Teile der Weltwirtschaft durch die Entstehung transnationaler Lieferketten und damit die Verwandlung des herkömmlichen Kapitalismus in eine neue, globalisierte Spielart: den Supplychain-Kapitalismus.
Der Aufstieg des Supplychain-Kapitalismus
Supplychains halten seit Anfang der 1980er Jahre vermehrt Einzug in die Management-Literatur, und auch wenn man sich heute damit befassen will, wird man vor allem in den Büchern und Aufsätzen der Wirtschaftswissenschaft oder der Managementtheorie fündig. Dort wird die Geschichte als eine Erfolgsgeschichte moderner Managementmethoden in einer sich zunehmend globalisierenden Welt erzählt.
Am Anfang steht die Feststellung, dass die Prozesse zur Herstellung, Distribution und Vermarktung von Produkten vielfältig sind und ganze Ketten von Wertschöpfungsstationen durchlaufen, die der Management-Theoretiker Michael Porter »Value Chains« nennt (Porter 1985).
Mit der Ausbreitung von modernen Kommunikationsmitteln reduzieren sich die Transaktionskosten so sehr, dass es wirtschaftlich wird, die einzelnen Stationen der Wertschöpfung an unterschiedliche Akteure outzusourcen (Sanyal 2012). Dies ermöglicht die Verteilung der Produktion über die ganze Welt, während der Markt dafür Sorge trägt, dass sich alle Stationen entlang des optimalen Preis-/Leistungsverhältnis verteilen.
Schon seit David Ricardo wissen wir, dass Länder, die sich auf bestimmte Produkte spezialisieren, einen »komparativen Vorteil« haben, so dass sich die globale Werkbank entsprechend ausdifferenziert (Christopher/Daco 2012). Zum Beispiel spezialisierte sich Japan bald auf Unterhaltungselektronik, Bangladesch auf Textilien, Deutschland auf Autos und Maschinen und die USA eben auf Software und Marketing. Überdies standardisierte die »Inter national Standards Organization« in den 1960er Jahren den Schiffscontainer und gibt damit der Globalisierung einen Extraschub. Mit dem ISO-Container-Standard können Be- und Entladung von LKWs, Zügen und Schiffen enorm beschleunigt und die weltweite Logistik viel effizienter organisiert werden (Sanyal 2012; Heilweil 2021).
Es sei außerdem auf die internationale Standardisierung des multilateralen Handels durch das GATT-Abkommen und schließlich auf die Gründung der Welthandelsorganisation (WTO) hingewiesen, die für einheitliche Handelsregime und den Abbau von Zöllen und anderen Handelsbarrieren sorgte. Dazu kommen die vielen multilateralen Freihandelsabkommen der letzten Jahrzehnte wie etwa TRIPS, CETA und TTIP, die Handelsregime weltweit harmonisieren und damit die Transaktionskosten des globalen Handels weiter reduzieren (Nicita/Ognivtsev/Shirotori 2013).
Mit der Ausbreitung der Supplychains wurde die Globalisierung erst so richtig angeschoben. Zwar gab es auch vorher internationale Konzerne. Das waren jedoch Unternehmen, die ein internationales Filialnetz unterhielten oder international Handel trieben. Der Supplychain-Kapitalismus sortiert die Länder der ganzen Welt in eine globale Arbeitsteilung. Das führte einerseits zu enormem wirtschaftlichen Wachstum in manchen Regionen. Während noch Ende der 1980er Entwicklungsländer etwa 5% des weltweiten Handels beisteuerten, sind es heute fast 50%, und 80% aller gehandelten Güter durchlaufen globale Supplychains (Vaughan-Whitehead 2022).
Kurz: Supplychains waren einfach eine gute Idee zur rechten Zeit, die sich deswegen entlang von technischen Innovationen und politischen Entscheidungen am Markt durchgesetzt haben und seitdem für günstige Produkte im Westen und für wachsenden Wohlstand im globalen Süden sorgen.
Der Aufstieg des Supplychain-Kapitalismus nach Anna Tsing
Solche und ähnliche Beschreibungen des Supplychain-Kapitalismus sind zwar nicht völlig falsch, aber unvollständig und ahistorisch. Anna Tsing erzählt in ihrem Buch „The Mushroom at the End of the World“ den Aufstieg der Supplychains ganz anders (Tsing 2015: 107ff.), und zwar als eine Geschichte zweier konkurrierender Mächte: Japan und die USA. Als 1853 amerikanische Kanonenboote an der Küste vor Japan die Öffnung der japanischen Volkswirtschaft für den internationalen Handel erzwangen, sorgte das dort für einen politischen Umsturz und führte zu einer rapiden Verwestlichung der japanischen Kultur. Es entwickelte sich schnell eine moderne Ökonomie mit Fabriken, Banken und Handel. Anfang des 20. Jahrhunderts formten sich bereits die ersten Konglomerate, also Firmenstrukturen, die Unternehmen mit unterschiedlichen Funktionen unter einem Konzerndach etablierten. Dabei ging es darum, die Industrieproduktion mit starken Handelsunternehmen zu flankieren und mittels hauseigener Banken zu finanzieren. Nach dem verlorenen Zweiten Weltkrieg formierten sich die Konglomerate neu als »Enterprise Groups« und fingen an, Zulieferer in anderen Ländern zu gründen. Finanziert wurde das durch Kredite der Banken, die die Mischkonzerne an die gegründeten Zulieferer und zusammen mit eigenem Know-how weiterreichten. Die Zulieferer waren damit zwar formell unabhängig, aber wirtschaftlich doch abhängig, so dass sie bequem aus Japan gesteuert werden konnten.
Die Vorteile waren vielfältig: man konnte auf die Ressourcen des jeweiligen Landes zugreifen, ohne politische oder öffentlichkeitsbedingte Risiken einzugehen. Der Zulieferer übernahm formell die Verantwortung für Arbeiter*innen und Umwelt und kapselte die sich daraus ergebenden Risiken und potenziellen Kostenfaktoren vom Leitunternehmen ab (»We don’t employ anyone in Haiti«).
Gleichzeitig konnten die Leitunternehmen die Zulieferer schnell austauschen, etwa wie im von Tsing geschilderten Beispiel, die Holzarbeiter*innen von den Philippinen schnell nach Indonesien übersetzten, wenn dort der Wald knapp wurde (vgl. Tsing 2015: 116). Das bedeutet, dass die Zulieferer in eine kompetitive Situation versetzt wurden, die ihre Verhandlungsmacht mit den Leitunternehmen von vornherein begrenzte (Danielsen 2019).
Ein weiterer Faktor waren Einfuhrbeschränkungen in den USA, die aus Angst vor der immer größer werdenden japanischen Konkurrenz eingerichtet wurden. Südkorea war eines der ersten Länder, das vom frühen Supplychain-Boom durch japanische Unternehmen profitierte und entsprechend eine eigene industrielle Basis ausbauen konnte.
Diese konnte dann wiederum dazu genutzt werden, um die Produkte von dort in die USA zu verschiffen und so die Einfuhrbeschränkungen zu umgehen. Die japanischen Leitunternehmen achteten dabei sehr genau darauf, dass Südkorea immer einen oder zwei technologische Schritte hinter den japanischen Konzernen verblieben. Gleichzeitig begannen die Zulieferer in Korea ihrerseits weniger anspruchsvolle Arbeiten an Zulieferer in anderen Regionen auszulagern. Das Modell begann sich global zu streuen. In Japan wurden diese Supplychain-Verzweigungen mit der Metapher der »Fliegenden Gänse« beschrieben. Die Leitgans fliegt voraus, die anderen sortieren sich dahinter, aber alle fliegen in eine Richtung.
Unter dem Druck des Erfolgs der japanischen Industrie und ihrem Supplychain-Modell begannen in den späten 1980er Jahren auch amerikanische Investor*innen die US-Industrie umzubauen. Unternehmensfusionen, Aufkauf durch Hedgefonds, das Abspalten und Auslagern von unwirtschaftlichen Unternehmensteilen waren bis einschließlich der gesamten 1990er Dauerthema in den USA und mit etwas Zeitverzug auch in Europa.
Und hier sind wir zurück bei Nike. Der Konzern ging ursprünglich aus dem amerikanischen Handelsarm eines japanischen Konzerns hervor, der bereits umfassende Erfahrung mit der Organisation von Supplychains hatte. Die amerikanische Ausgründung konnte dieses Wissen mit dem amerikanischen Know-how zu Marketing und Branding kombinieren, was zu dem sagenhaften Erfolg des Unternehmens führte. Ähnlich wie das amerikanische Kanonenboot, dass im 19. Jahrhundert die Öffnung der japanischen Ökonomie erzwang, haben japanische Lieferketten eine Umorganisation der amerikanischen Wirtschaft erzwungen. Oder wie es die Figur Joseph Yoshinobu Takagi in dem Film Stirb Langsam (Die Hard) ausdrückt: »We’re flexible, Pearl Harbor didn’t work out so we got you with tape decks.«
Supplychains sind historisch betrachtet nicht einfach Managementideen, die sich am Markt durchgesetzt haben, sondern es sind bewusst in die Welt gesetzte hierarchische Strukturen, die zur Minimierung von Verantwortlichkeit bei gleichzeitiger Maximierung von Kontrolle geschaffen wurden. Damit wird auch klar, dass es dabei nicht in erster Linie um wirtschaftliche Zusammenarbeit geht, sondern um Macht.
Abhängigkeit und Austauschbarkeit
Um diese Machtstrukturen genauer zu analysieren, erweist sich der Rückgriff auf den viel zu wenig rezipierten Aufsatz von Richard M. Emerson Power-Dependence Relations aus dem Jahr 1962 als nützlich (Emerson 1962) 1.
Emerson definiert hier die Macht zwischen Akteuren als die wechselseitige Abhängigkeit dieser Akteure. Macht ist bei ihm also immer ein relationales Verhältnis und es ist umgekehrt proportional zur Abhängigkeit in der Relation:
Wenn A abhängig von B und B abhängig von A ist, dann ist die Macht von A über B B’s Abhängigkeit von A und umgekehrt. Dass Abhängigkeit und damit auch Macht immer wechselseitig gedacht wird, widerspricht dabei nicht der Beobachtung, dass es durchaus Machtungleichgewichte gibt. So kann A weit weniger abhängig sein von B als B von A (Emerson 1962).
Stellen wir uns eine ausgeglichene Beziehung vor: A und B sind hier zwei Kinder aus der Nachbarschaft. Die beiden Kinder spielen gern zusammen, denn allein spielen ist langweilig. Sie sind also beide von der wechselseitigen Kooperation abhängig. Würde A sich weigern, mit B zu spielen, könnte B sein Ziel (gemeinsames Spielen) nicht erreichen. Aber A könnte es ebenso wenig.
Nun zieht eine neue Familie in die Nachbarschaft, und A lernt C kennen, das gleichaltrige Kind der neuen Familie. Die beiden freunden sich an. Das verändert auch die Beziehung zwischen A und B, da A jetzt eine alternative Spielpartnerin hat. A hat nun mehr Macht über B, da er weniger abhängig von B ist als B umgekehrt von A. B müsste nun einen Balanceakt vollziehen, um dieses Machtungleichgewicht wieder auszutarieren. Dafür hat sie vier Optionen.
Sie kann ihre eigene Motivation, mit A zu spielen, zügeln (»A ist eh doof«).
Sie kann sich eine alternative Ressource erschließen, also zum Beispiel eine andere Spielkameradin finden (eine Spielkameradin D zum Beispiel).
Sie kann sich selbst als Spielkameradin für A wieder attraktiver machen (indem sie zum Beispiel in ein neues Legoset investiert), damit A wieder lieber zu B zum Spielen kommt.
Sie kann As Zugang zu alternativen Ressourcen (in diesem Fall also zu C) versperren. Sie kann zum Beispiel Cs Familie überreden, wieder wegzuziehen (schwierig), oder sich mit C verbünden (leichter)
Wenn wir dieses einfache Framework auf die Zulieferketten anwenden, ergibt sich ein klares Bild: Um einen Nike-Schuh herzustellen, sind alle Akteure (das Leitunternehmen sowie alle Zulieferfirmen) wechselseitig voneinander abhängig. Jedoch gibt es Unterschiede: Jeder Einzelne der Zulieferer – egal ob er Stoffe, Plastik oder Kordeln herstellt – ist aus Sicht des Leitunternehmens recht einfach austauschbar (Balanceakt 2). Es gibt viele konkurrierende Unternehmen und selbst wenn es sie nicht gäbe: das Wissen um Stoffe, Plastik und Kordeln herzustellen ist schnell ins Werk gesetzt.
Das Leitunternehmen hingegen, Nike, betreut zwar nur die Marke und andere Rechte, aber diese Rechte sind dank internationaler Abkommen wie TRIPS und durch die WTO global geschützt (Balanceakt 4). Die Leitunternehmen kontrollieren daher monopolistisch den Zugang zur Wertschöpfung. Für die Zulieferer ergibt sich dadurch eine enorme Abhängigkeit, denn ohne den Zugang zu Nikes Verkaufsnetzwerk und seiner »Brand-Recognition« sind die Produktivitätskapazitäten der Zulieferer völlig nutzlos. Dadurch ist Nike der einzige Akteur in diesen wechselseitigen Beziehungen, der weniger von den anderen abhängig ist, als diese von ihm. Die »Fliegenden Gänse« sind also in Wirklichkeit eine Hierarchie der Macht, die von einem durch globale Gesetzgebung geschützten Leitunternehmen angeführt und ausgebeutet werden. Je tiefer man in die Verästelung der Lieferketten hinabsteigt, desto austauschbarer werden die Unternehmen und sind in Ableitung davon, entsprechend weniger fähig, erarbeitete Margen zu kassieren.
Empirisch lässt sich dieses Ungleichgewicht gut am Smartphone-Markt beobachten. Seit der Markt für iPhones gesättigt ist und die Verkaufszahlen stagnieren, sinkt entsprechend der Umsatz bei Foxconn, dem chinesischen Fabrikanten der iPhones, während Apple, das vor allem die Marke und die Patente kontrolliert, seinen iPhone-Umsatz um 20% steigern konnte (Danielsen 2019).
Im Supplychain-Kapitalismus gibt es nicht mehr nur die Ausbeutung von Arbeiter*innen durch Kapitalist*innen, sondern auch die Ausbeutung von Kapitalistinnen untereinander. Es entsteht eine globaleHierarchie der Kapitalist*innen, bei der sich nur die Zulieferer noch mit einfachen Arbeiter*innen herumschlagen müssen. Diese Zuliefer-Kapitalist*innen sitzen meist in eher strukturschwachen Ländern und müssen, um überhaupt am Spiel der globalen Lieferketten mitspielen zu dürfen, ihre Produktivitäts-Margen den Leitunternehmen opfern. Zu diesem Schluss kommt zum Beispiel Dan Danielsen:
»The fierce competition among developing-country suppliers in many business sectors will likely require supplier firms to make these innovations to gain access to or remain competitive in global supply chains with gains likely captured by buyer firms or shared across global chains«
(Danielsen 2019)
Und nun landen wir in einem scheinbaren Paradox: Die Firmen, die sich eigentlich nur noch mit dem Immateriellen beschäftigen – z.B. Nike oder Apple – sind am wenigsten austauschbar. Die Firmen, die die materiellen Komponenten beisteuern – die Fabrik, die Maschinen, die Arbeiter*innen, die physischen Produkte – sind das Austauschbare schlechthin.
Relationale Dematerialisierung
An dieser Stelle sind wir gezwungen, uns zu fragen, was Materialität eigentlich bedeutet. Ist es damit getan, das Materielle als physikalisch beschreib- und messbare (Energie, Masse) Entitäten zu definieren? Was wäre mit einer solchen essentialistischen Definition gewonnen? Natürlich sind solche Verweise auf Materialität wichtig, um über reale Effekte auf Umwelt und Menschen zu verweisen. Lieferketten extrahieren materielle Ressourcen und beuten menschliche Arbeit aus. Doch das Interessante ist doch gerade die Diskrepanz zwischen dem wirklich Materiellen und dem, was wir als tatsächlich harte Grenze des Mach- und Denkbaren empfinden. Nur diese Diskrepanz ermöglicht die Materialitätsvergessenheit, die es nötig macht, die Materialität überhaupt so direkt zu adressieren. Es ist, als gäbe es zwei widerstrebende Materialitäten: die eine, tatsächliche Materialität, die aber durch ihre zunehmende Austauschbarkeit aus dem Fokus der Aufmerksamkeit rutscht; und eine ›gefühlte‹ Materialität, die sich durch ihre tatsächlich empfundene Widerständigkeit unsere Grenzen absteckt, obwohl die ihr zugrunde liegenden Mechanismen rein ausgedachte und von Menschen ins Werk gesetzte sind (Markenrechte, Patente, Lizenzen, Verträge etc.).
Diese andere Materialität definiert sich durch kritische Abhängigkeiten, das heißt am Ende: Nicht-Austauschbarkeiten. Diese andere Materialität lässt sich mit Katharina Hoppe vom Relationalen her denken. Hoppe hat dies unter anderem in ihrem mit Thomas Lemke veröffentlichten Band Neue Materialismen zur Einführung vorgeschlagen (Hoppe/Lemke 2022: 164f.), aber noch einmal deutlicher in einem kürzlich veröffentlichten Interview:
»Wenn man konsequent von der Einsicht in die Relationalität her denkt und die Entstehung der Welt als offenen Prozess versteht, dann kann Materie als aktiv, aber auch als schlapp und passiv vorkommen. Dies wäre dann eben ein Ergebnis der jeweiligen Analyse und nicht ihre Voraussetzung«
(Hoppe via Schätzlein 2023)
Hoppe versucht, das Materielle von der Relationalität her zu denken und Materie an sich erstmal noch keine hervorgehobene Rolle zuzuweisen. Diese Rolle entsteht erst in der Verbindung, das heißt in der Interaktion.
Wie Hoppe denkt auch Anna Tsing in Konzepten von Verbundenheit.2 Tsing spricht nicht direkt von Materialität und Immaterialität, doch sie problematisiert ein verwandtes Konzept: Die Skalierung. Skalierung bedeutet für Tsing ein nicht-transformatives Wachstum. Ein Wachstum also, das zwar neue Verbindungen eingeht, sich von diesen Verbindungen aber nicht verändern lässt.
Eine skalierbare technische Infrastruktur ist zum Beispiel eine, bei der es strukturell kaum einen Unterschied macht, ob sie von 10 oder 10 Millionen Menschen verwendet wird. Die meisten modernen Geschäftsmodelle basieren auf einer solchen Idee von Skalierung bzw. Skalierbarkeit.
Tsing wendet aber ein, dass diese Skalierbarkeit immer einen Preis hat. Das zu Skalierende muss, so Tsing, immer aus einem Gewebe von Verbindungen herausgelöst werden. Verbindungen müssen gekappt werden, um Skalierbarkeit zu gewährleisten. Tsing gibt das Beispiel von Zuckerrohrplantagen in der Kolonialzeit in Südamerika. Die Portugiesen merkten bald, dass eine wesentliche Voraussetzung der Skalierbarkeit die Entwurzelung und damit die Austauschbarkeit der Elemente ist:
»They crafted self-contained, interchangeable project elements, as follows: exterminate local people and plants; prepare now-empty, unclaimed land; and bring in exotic and isolated labor and crops for production. […] The interchangeability of planting stock, undisturbed by reproduction, was a characteristic of European cane. … Under these conditions, workers did, indeed, become self-contained and interchangeable units«
(Tsing 2015)
Die Herstellung von Austauschbarkeit erweist sich als wesentliches Basiselement kapitalistischer Wachstumskonzeptionen. Und diese Austauschbarkeit wird über das Abkapseln von Verbindungen und das Reduzieren von Abhängigkeiten hergestellt. Erst diese »relationale Dematerialisierung« reduziert die Reibung in den Prozessen und macht globale Lieferketten überhaupt möglich. Der Schiffscontainer ist somit nicht nur das logistische Kernstück der Globalisierung. Es ist auch zentrales Sinnbild einer Form von »relationaler Dematerialisierung«, die alle unnötigen Verbindungen abkapselt und jedes physische Gut zu einer austauschbaren Einheit macht. Der ISO-Container ist absolut austauschbar, das ist sein ganzer Sinn. Und dieser Sinn besteht am Ende im Verschwinden des Materiellen als einer widerständigen Realität.3
Plattformen als Infrastruktur der Austauschbarkeit
Der ISO-Container nimmt in dieser Hinsicht die Digitalisierung vorweg. In der Digitalisierung geht es, wie bei den Lieferketten, um Skalierung durch Austauschbarmachung. Die digitale Kopie hat eine neue Qualität von Austauschbarkeit in die Welt gesetzt, die eine bis dahin ungekannte Skalierung erlaubt. Es ist wirtschaftlich egal, ob ein digitaler Song 10 oder 10 Milliarden Mal kopiert und in Sekundenbruchteilen distribuiert wird. Diese Eigenschaft des Digitalen hat unsere Leben in vielen Hinsichten bequemer gemacht, aber auch zu neuen Problemen geführt.
Zum Beispiel: Wie organisiert man Wirtschaft unter der Bedingung der Unknappheit (Staab 2020)? Die Antwort auf dieses Problem sind Plattformen. Plattformen radikalisieren den Prozess der relationalen Dematerialisierung und skalieren auf eine Weise, die man in der physischen Welt noch nicht gesehen hat. Der Begriff »Plattform« kommt ursprünglich aus dem Französischen und ist eine Zusammensetzung aus altfranzösisch plat (flach) und forme (von lateinisch forma). Er wurde in der frühen Neuzeit vor allem in Bezug auf eine militärische Architektur verwendet, eine etwas erhöhte Fläche, die sich gut eignete, Katapulte und später Kanonen darauf zu positionieren. Kanonen sollten einerseits erhöht stehen, um eine optimale Reichweite zu erzielen, andererseits musste gewährleistet sein, dass sie schnell austauschbar waren. Die Austauschbarkeit ist auch hier von Anfang an entscheidend.
Eine sehr einfache Definition von »Plattform« wäre »Infrastruktur des Austausches«. Das ist sie aber auf zweifache Weise. Zum einen sind Plattformen Orte, an denen man sich austauscht: der Ort, wo man in und aus dem Zug steigt (zumindest im Englischen); der Ort, an dem man Geschichten teilt, Handel betreibt, flirtet oder ein Taxi heranruft. Zum anderen sind Plattformen Orte der Austauschbarmachung. Auf Plattformen kann ich nur als austauschbare, in gewisser Weise standardisierte Variante meiner selbst teilnehmen, als Dividuum statt als Individuum (vgl. Seemann 2021: 113f.). Das erlaubt es anderen, mich über standardisierte Suchen zu finden und umgekehrt auch mir, andere zu finden und mich zu verbinden. Die Verbindung über die Plattform verbleibt also immer unter dem Vorbehalt der Austauschbarkeit, was den Austausch für alle vereinfacht und die Menge an potenziellen Verbindungen für jeden Einzelnen erweitert. Diese Skalierung geht aber immer auch mit der eigenen Austauschbarkeit einher, denn die nächste Fahrerin, die nächste Unterkunft, das nächste Date ist nur einen Klick oder Rechts-Swipe entfernt. Das gilt zumindest für die Interaktionen, die exklusiv auf der Plattform verbleiben.
Die Unaustauschbarkeit des Graphen
Dieser generellen Austauschbarkeit der einzelnen Verbindung steht allerdings eine große Nicht-Austauschbarkeit gegenüber: die des Graphen. Ein Graph, oder genauer ein »Netzwerkgraph«, ist erstmal die Beschreibung eines Netzwerkes. Individuell ergibt sich ein je einzigartiges Netzwerk an Verbindungen, die den Nutzenden an die Plattform bindet und ein tatsächliches Abbild seiner sozialen und kulturellen Bindungen ist. Und genau in dem Unterschied zwischen austauschbarer Verbindung und unaustauschbarem Graphen residiert die Macht der Plattformen.
»Graphen sind ebenjene unterliegende Architektur, die eine Plattform nicht selbst herstellen kann. Eine Plattform kann die Voraussetzungen schaffen, um die Verbindungen zu ermöglichen – als erwartete Selektion potentieller Verbindungen. Aber der Graph einer Plattform ist nur zu etwas nütze, wenn er in den konkreten Verbindungen mit einer Realität außerhalb der Plattform korreliert: echte Musikleidenschaften, bedeutende Freundschaften, bedeutende Bedürfnisse, bedeutende Interessen, bedeutende Orte, Wege oder Leidenschaften.«
(Seemann 2021: 154)
Diese Macht wird in der ökonomischen Theorie gerne als »Netzwerkeffekt« oder »Netzwerkexternalität« bezeichnet.4
Sie sorgt dafür, dass Menschen einerseits einen starken Anreiz haben, sich großen Netzwerken anzuschließen (es locken viele potenzielle Verbindungen) und bindet andererseits Menschen langfristig an Plattformen (der sogenannte »Lock-in-Effekt«).
Netzwerkeffekte kann man also auch als aggregierte Abhängigkeiten betrachten. Alle wechselseitigen Abhängigkeiten der Nutzenden einer Plattform übersetzen sich – sofern sie über die Infrastruktur der Plattform ausagiert werden – in eine Abhängigkeit von der Plattform selbst. Und genau hier liegt die Plattformmacht als relative Unaustauschbarkeit. Das gilt sowohl für kleinere Netzwerke – etwa Nachbarschaftsnetzwerke oder Unternehmens-Chats – als auch für größere, wie Dating-Apps, Lieferdienste oder Übernachtungsvermittlungs-Apps. Dabei gilt: Große Plattformunternehmen kontrollieren entsprechend große Graphen. Facebook kontrolliert den »Social Graph«, Google kontrolliert den »Interest Graph«, Amazon kontrolliert den »Consumption Graph« usw. (Valdes 2012).
Strategisch gesehen steht die Inbesitznahme eines Graphen folglich im Zentrum einer jeden erfolgreichen Plattformgeschichte.5 Neue Plattformen haben das Problem, dass auf ihnen noch keine Interaktionen stattfinden, weswegen sie für Nutzende zunächst uninteressant sind. Es ist das typische Henne-Ei-Problem: Erst mit der Interaktion entsteht die Attraktivität, die die Interaktion möglich macht. Historisch wurde dieses Problem dadurch gelöst, dass Plattformen initial einen bereits etablierten Interaktionszusammenhang aufgreifen und versuchen, ihn in die Plattform zu integrieren. Bei Facebook waren es zunächst Elite Campus, die die Grundlage des frühen Facebook-Wachstums bildeten, bei Amazon Buchbegeisterte, bei Paypal Ebay-Nutzende (vgl. Seemann 2021: 145ff.). Während die Leitunternehmen in der Supplychain also ihre Immaterialgüterrechte einsetzen, um sich an die Spitze der Austauschbarkeits-Hierarchie zu setzen, spielen diese Rolle bei den Plattformunternehmen die aggregierten Abhängigkeiten ihrer Nutzenden: der Graph.
Der Plattformmerkantilismus
Die Gemeinsamkeit des Supplychain-Modells mit dem Plattform-Modell ist also, dass sie beide durch geschicktes Herstellen von Austauschbarkeit und Abhängigkeit eine Super-Struktur oberhalb des herkömmlichen Kapitalismus etablieren, die andere kapitalistische Akteure in eine Hierarchie zwingt, in der sie sich selbst unaustauschbar gemacht haben und deswegen alle anderen ausbeuten können. Aber in der Form der Unaustauschbarkeit unterscheiden sie sich grundlegend.
Das Supplychain-Modell folgt noch der klassischen Logik des Kapitalismus. Diese kann man wie folgt zusammenfassen: Das Eigentum an Produktionsmitteln (Kapital) wird staatlich geschützt und etabliert eine hinreichende Nichtaustauschbarkeit (ein mehr oder weniger lokales Monopol), während das Unternehmen die Aufgaben der Arbeiter*innen hinreichend standardisiert – also relational dematerialisiert – um ihre Austauschbarkeit zu gewährleisten. Die Tatsache, dass im Supplychain-Modell die Produktionsmittel der Leitunternehmen immaterielle Werte wie Marken- und Verwertungsrechte sind, statt Gebäude und Maschinen, ist zwar eine historische Neuerung; sie tastet das Grundprinzip des Kapitalismus aber nicht an. Vielmehr radikalisiert es das kapitalistische Modell, weil das immaterielle Kapital (weltweit geschützte Immaterialgüterrechte) in der Praxis noch unaustauschbarer ist, als es das materielle Kapital (Gebäude, Maschinen) je war.
Das Plattformmodell weicht hier entscheidend ab. Indem es als Machtgrundlage die Unaustauschbarkeit des durch ihn kontrollierten Graphen etabliert, macht es sich vom Ordnungsregime des Eigentums – und damit der Durchsetzungsmacht des Staates – ein gutes Stück unabhängig. Plattformen haben kein rechtliches Eigentum an ihrem Graphen. Es gibt keine Möglichkeit Dritten gegenüber einen Rechtsanspruch für einen Graphen zu reklamieren, denn Interaktionszusammenhänge sind rechtlich nicht eigentumsfähig. Das brauchen Plattformen aber auch nicht. Ihre Macht basiert auf der direkt ausgeübten Kontrolle über den Graphen mittels ihrer technischen Infrastruktur (Seemann 2021: 117ff.). Über diese können Plattformen zum Beispiel vorgeben, welche Arten von Interaktionen man auf ihnen durchführen darf (Infrastrukturregime), sie können Nutzende ein- und ausschließen (Zugangsregime) und sie können mittels algorithmischer Kontrolle bestimmte Interaktionen wahrscheinlich oder unwahrscheinlich machen (Query-Regime).
Damit gleicht die Struktur der politischen Ökonomie der Plattformen viel eher der des merkantilistischen Staats als der des kapitalistischen Unternehmens. Im Merkantilismus war es der sich gerade formierende Staat, der seine Kontrollinstrumente – Steuern, Zölle, das Vergeben von Monopolrechten, im Zweifel Gewalt (Shovlin 2014) – direkt dazu einsetzte, die eingehenden und ausgehenden Ressourcen zu kontrollieren und so seine Staatsfinanzen mittels extrahierter Renten aufzubessern (Magnusson 2015: 54ff.). Und ähnlich wie bei Plattformen basierte im Merkantilismus ein Großteil dieser Ressourcen auf der Ausbeutung von eroberten Gefilden – Kolonien im Falle der Staaten, okkupierte Graphen im Falle der Plattformen.
The Means of Connection
Wie schon im Supplychain-Kapitalismus setzt sich auch bei den Plattformen eine Kapital-Kapitalistische Ausbeutung ins Werk. Zwar passiert auch im Plattformmerkantilismus die Ausbeutung oft auf Kosten von Arbeiter/*innen (deren Arbeiterstatus aber oft durch Selbstständigkeit verschleiert wird), aber eben nicht nur. Vielmehr geht die Ausbeutung auch auf Kosten von klassischen Kapitalist/*innen. Diese sind nämlich zunehmend darauf angewiesen, ihre Kundschaft über Plattformen zu erreichen und müssen, um Zugang zu ihnen zu bekommen, ihre Margen an die Plattform abtreten. Die vielen Klagen der Händler*innen über den Amazon Marketplace (Bundeskartellamt 2021), die prekäre Lage der Smartphonehersteller in Googles Handset-Alliance (Amadeo 2018) und die viel kritisierte 30% Abgabe auf Apples App-Store (Roth 2022) sind nur die prominentesten Beispiele dieser Ausbeutung.
Rufen wir uns das Zitat von Tom Godwin in Erinnerung:
»Uber, the world’s largest taxi company, owns no vehicles. Facebook, the world’s most popular media owner, creates no content. Alibaba, the most valuable retailer, has no inventory. And Airbnb, the world’s largest accommodation provider, owns no real estate.«
Wir können nun besser verstehen, wie das tatsächliche materielle Kapital (Immobilien, Autos, Inventar) zur Nebensächlichkeit wird, wenn man als Plattform die Verbindungen und damit Abhängigkeiten kontrolliert. Im Plattformmerkantilismus gilt nicht mehr der als mächtig, der die »Means of Production« besitzt, sondern wer die »Means of Connection« kontrolliert.
Fazit
Plattformen, so scheint es, haben ihren Zenit bereits überschritten. Der »Techlash« ruinierte das Image von Silicon Valley (Kuhn 2018). Große »Unicorns« wie WeWork und Uber sind bankrottgegangen oder mussten ihre Erwartungen enorm reduzieren (Karabell 2019). Rebecca Giblin und Cory Doctorow sprechen von »enshittification« der großen Plattformen und meinen damit die zunehmende Extraktion der Abhängigkeiten im Graphen zur Erhöhung des Profits (Giblin/Doctorow 2022). Plattformen sind toxisch geworden. Seit Elon Musk Twitter kaufte und es zu X umfunktionierte, hält sich die Stimmung, dass es mit Social Media insgesamt zu Ende geht (Bogost 2022).
Darüber hinaus haben sich ganz klassisch kapitalistische Konzerne wie der taiwanesische TSMC durch Forschung und Entwicklung einen sehr konkreten technologischen Vorsprung und damit eine Unaustauschbarkeit erarbeitet, die die Plattformunternehmen auf dem falschen Fuß erwischt hat (Campbell 2021). Sie alle sind nun von den sehr klassisch materiellen Produktionslinien von TSMC abhängig, der heute fast ein Monopol auf die Produktion der leistungsfähigen Chipgenerationen hat. Gleichzeitig ist es gerade die generative KI, die als neue Leittechnologie die Imaginationen und damit die Gelder der Venture-Kapitalgeber*innen auf sich zieht. Generative KI ist eine Technologie, die zwar auch in Plattformen Anwendung findet, aber grundsätzlich erstmal wegführt von der zwischenmenschlichen Interaktion: Eine Technologie, die sogar auf lange Frist das Potential in sich birgt, die Abhängigkeiten der Menschen untereinander allgemein zu reduzieren (Seemann 2023).
Das Plattformparadigma wird genauso wenig sterben, wie es das Supplychain-Paradigma getan hat. Es wird nur aufhören, das meistdiskutierte Phänomen unserer Zeit zu sein. Es werden auch in Zukunft neue Wege gefunden werden, Austauschbarkeitshierarchien zu etablieren und sich an ihre Spitze zu setzen. Und genau darum geht es mir: Das Framework zur Beschreibung von Macht durch wechselseitige Abhängigkeit und Austauschbarkeit scheint mir universell genug zu sein, um es auch auf kommende Ausbeutungsparadigmen anzuwenden. Es bietet Anknüpfungspunkte für Analysen von Abhängigkeitsverhältnissen wirtschaftlicher Akteure, die nicht mehr den Markt ins Zentrum stellen, sondern Macht. Das Framework ist damit grundsätzlich auf den Feudalismus ebenso anwendbar wie auf den Kapitalismus, den realen Sozialismus oder den Merkantilismus. All diese Wirtschaftssysteme sind nur unterschiedliche Ausgestaltungen von Abhängigkeitshierarchien mit den je etablierten Mechanismen ihres Managements. Dieser Essay soll somit ein noch unkonkretes Forschungsprogramm begründen, das viele weitere Anwendungsfälle der Theorie anschaut.
Literatur
Amadeo, Ron (2018) »Google’s iron grip on Android: Controlling open source by any means necessary«, Ars Technica, https://arstechnica.com/gadgets/2018/07/googles-iron-grip-on-an-droid-controlling-open-source-by-any-means-necessary/3/ (13.12.2023).
Bogost, Ian (2022) »The Age of Social Media Is Ending, The Atlantic«, https://www.theatlantic.com/technology/archive/2022/11/twitter-facebook-social-media-decline/672074/ (13.12.2023).
Bundeskartellamt (2021) »Proceedings against Amazon based on new rules for large digital companies (Section 19a GWB)«, Bundeskartellamt, https://www.bundeskartellamt.de/SharedDocs/Meldung/EN/Pressemitteilungen/2021/18_05_2021_Amazon_19a.html (13.12.2023).
Campbell, Charlie (2021) »Inside the Taiwan Firm That Makes the World’s Tech Run«, Time Magazin, https://time.com/6102879/semiconductor-chip-shortage-tsmc/ (13.12.2023).
Christopher, Chris G./Daco, Gregory (2012) »Ricardo’s ›comparative advantage‹ still holds true today«, Supply Chain Quarterly, https://www.supplychainquarterly.com/articles/665-ricardo-s-comparative-advantage-still-holds-true-today (13.12.2023).
Danielsen, Dan (2019) »Trade, Distribution and Development under Supply Chain Capitalism«, in Santos, Alvaro/Thomas, Chantal Trubek, David (2019) World Trade and Investment Law Reimagined – A Progressive Agenda for an Inclusive Globalization, London: Anthem Press, 121-131.
Engemann, Christoph (2016) »Digitale Identität nach Snowden. Grundordnungen zwischen deklarativer und relationaler Identität«, in Hornung, Gerrit/Engemann, Christoph (Hrsg.): Der digitale Bürger und seine Identität, Baden-Baden: Nomos, 23-64.
Emerson, Richard M. (1962) »Power-Dependence Relations«, American Sociological Review, Vol. 27, No. 1, 31-41, https://www.jstor.org/stable/2089716 (13.12.2023).
Giblin, Rebecca/Doctorow, Cory (2022) Chokepoint Capitalism: How Big Tech and Big Content Captured Creative Labor Markets and How We’ll Win Them Back, Boston: Beacon Press.
Grewal, David Singh (2008) Network Power – The Social Dynamics of Globalization, New Haven: Yale University Press.
Haskel, Jonathan/Westlake, Stian (2018) Capitalism without Capital: The Rise of the Intangible Economy, Princeton: Princeton University Press.
Heilweil, Rebecca (2021) »The history of the metal box that’s wrecking the supply chain«, vox.com, https://www.vox.com/recode/22832884/shipping-containers-amazon-supply-chain (13.12.2023).
Hoppe, Katharina/Lemke, Thomas (2022): Neue Materialismen zur Einführung, Berlin: Junius. Karabell, Zachary (2019) »Stumbles at Uber and WeWork Don’t Mean the End of Tech, Wired«, https://www.wired.com/story/stumbles-uber-wework-dont-mean-end-tech/ (13.12.2023).
Klein, Naomi (1999) No Logo – NO SPACE NO CHOICE NO JOBS, London: Flamingo.
Kuhn, Johannes (2018) »›Techlash‹: Der Aufstand gegen die Tech-Giganten hat begonnen, Sueddeutsche Zeitung, https://www.sueddeutsche.de/digital/digitalisierung-techlash-der-auf-
»Supply Chains: Trade and Economic Policies for Developing Countries, United Nations Conference on Trade and Development«, Study Series 55. https://unctad.org/system/files/official-document/itcdtab56_en.pdf (13.12.2023).
Pfeffer, Jeffrey/Salancik, Gerald R. (1978) The External Control of Organizations: A Resource Dependence Perspective, New York: Harper & Row.
Porter, Michael E. (1985) The Competitive Advantage: Creating and Sustaining Superior Performance, New York: Free Press. Roth, Emma (2022) »Spotify says Apple is ›choking competition‹ and ruining its audiobook store«, The Verge, https://www.theverge.com/2022/10/25/23423384/spotify-apple-competitive-behavior-antitrust-commission-audiobooks (13.12.2023).
Sanyal, Sanjeev (2012) »A Brief History of Supply Chains«, The Globalist, https://www.theglobalist.com/a-brief-history-of-supply-chains/ (13.12.2023).
Schätzlein, Emma (2023) »Katharina Hoppe: ›Die Neuen Materialismen wollen mit dem Anthropozentrismus brechen‹« (Katharina Hoppe im Interview mit Emma Schätzlein),
Seemann, Michael (2021) Die Macht der Plattformen – Politik in Zeiten der Internetgiganten, Berlin: Ch. Links Verlag.
Seemann, Michael (2023) »Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft«, Hans Boeckler-Stiftung Working Papers, https://www.boeckler.de/de/faust-detail.htm?sync_id=HBS-008697 (13.12.2023).
Shovlin, John (2014) »War and Peace – Trade, International Competition, and Political Economy«, in Philip J. Stern u. Carl Wennerlind (Hg.) (2014): Mercantilism Reimagined – Political Economy in Early Modern Britain and Its Empire, Oxford: Oxford University Press, 305-327.
Staab, Philipp (2019) Digitaler Kapitalismus – Markt und Herrschaft in der Ökonomie der Unknappheit, Berlin: Suhrkamp.
Tsing, Anna Lowenhaupt (2015) The Mushroom at the End of the World – On the Possibility of Life in Capitalist Ruins, Princeton: Princeton University Press.
Valdes, Ray (2012) »The Competitive Dynamics of the Consumer Web: Five Graphs Deliver a Sustainable Advantage«, Gartner Research, https://www.gartner.com/en/documents/2081316 (13.12.2023).
Vaughan-Whitehead, Daniel (2022) »Behind the Rise of Global
Wark, McKenzie (2021) Capital Is Dead: Is This Something Worse?, London/New York: Verso.
Fußnoten
Der Kürze halber lasse ich die weitergehende, theoretische Einbettung weg, in der Emerson heute meist gelesen wird: nämlich der Resource Dependence Theory/RDT (Pfeffer/Salancik 1978). ↩
Beide sind in dieser Hinsicht stark von der Philosophie Donna Haraways geprägt. ↩
Es ist deswegen kein Zufall, dass die Lieferketten genau dann wieder ins Bewusstsein rückten, als sie im Zuge der Coronapandemie zusammenbrachen. ↩
Mit David Singh Grewal bezeichne ich diese Macht allerdings auch als »Netzwerkmacht« (vgl. Seemann 2021: 104ff.; Grewal 2008). ↩
Einen Vorgang, den ich mit Christoph Engemann »Graphnahme« nenne (vgl. Seemann 2021: 146ff.; Engemann 2016). ↩
Dieser Text erscheint in der Akzente-Ausgabe „Automatensprache“ von Mai 2024, in dem auch viele andere tolle Texte zum aktuellen KI-Hype enthalten sind.
*******/
In einem Interview vom März dieses Jahres sprach Sam Altman, CEO von OpenAI, – der mächtigsten KI-Firma der Welt – einen Satz aus, der ihm sofort unangenehm wurde. Er sagte: „Der Weg zu AGI sollte ein gigantischer Machtkampf sein.“ AGI (Artificial General Intelligence) markiert innerhalb der Branche die Erreichung von menschengleicher, genereller Maschinenintelligenz und ist das offizielle Ziel aller KI-Startups und -Konzernabteilungen. Altman korrigierte sich schnell: Er wünsche sich diesen Machtkampf nicht, aber er erwarte ihn.
Der Satz fällt an der Stelle, als es im Interview um seinen eigenen Machtkampf um die Kontrolle von OpenAI geht. Wenige Monate zuvor, im November 2023, feuerte ihn das Board des Unternehmens überraschend als Geschäftsführer. Die Nachricht verbreitete sich wie ein Lauffeuer und da das Board nur sehr vage Andeutungen über die Gründe machte, spekulierte die halbe Welt über den plötzlichen Rausschmiss.
Es ist wichtig, dabei zu verstehen, dass OpenAI keine Firma wie andere Firmen ist. Sie wurde bewusst als Non Profit Organisation (NGO) gegründet, um ethisch verantwortungsvolle KI-Forschung sicher zu stellen, doch unter Altman etablierte sie einen For-Profit-Arm, um Milliarden Dollar an Venture Capital einsammeln zu können, die nötig wurden, um die immer teurer werdenden KI-Modelle zu finanzieren. Das Board aber ist Teil der NGO-Struktur und hat die Aufgabe, über die ethischen und verantwortungsvollen Standards der Organisation zu wachen und hat über alle Geschäftsfelder das letzte Wort. Ein Rausschmiss des CEO ist der letzte Nothebel zur Sicherung dieser Kontrolle und genau so begründete das Board auch seine Entscheidung: Es habe das Vertrauen in Altman verloren.
Doch innerhalb weniger Tage änderte sich alles. Altman hatte es geschafft, einen Großteil der Mitarbeiter auf seine Seite zu ziehen, die auf einmal in einer Petition mit ihrer Kündigung drohten, und Microsoft, der wichtigste Geldgeber und Eigentümer der teuren Serverinfrastruktur, auf der OpenAI die Modelle trainiert und betreibt, stellte Altman in einer Blitzaktion als Chef einer neuen KI-Abteilung ein, die zudem die Bereitschaft signalisierte, auch alle anderen OpenAI-Mitarbeiter aufzunehmen.
Das Board hatte in dem Moment keine andere Wahl mehr als seine Entscheidung rückgängig zu machen. Altman kehrte nach weniger als einer Woche zurück auf seinen CEO-Posten und stattdessen wurde nun das Board neu organisiert.
In dem Interview reflektiert Altman überraschend offen, dass das Board rechtlich befugt war, ihn zu feuern, was seinen letztendlichen Sieg zu einer Art „Governance Failure“ der Organisation mache. Das ist eine niedliche Umschreibung für einen „Coup“.
Wenn Altman recht hat, wird diese Episode nur die erste öffentlich wahrnehmbar ausgetragene Schlacht im größeren Machtkampf um die Zukunft der KI-Technologie gewesen sein, und es werden noch viele folgen. Dass sich Silicon Valley gerade immer mehr zu „Game of Thrones“ verwandelt, hat einen tieferen Grund: Das, was bei OpenAI im Kleinen passierte, ist nur eine Vorahnung dessen, was der gesamten Welt bevorsteht:
KI ist ein Coup.
Einführung
Will man über Künstliche Intelligenz und Demokratie nachdenken, stellt sich als erstes die Frage, von welcher KI und von welchem Konzept von Demokratie wir sprechen. Beide Begriffe sind auf ihre eigene Weise unscharf.
Sprechen wir über aktuell existierende KI-Systeme, wie es sie mittlerweile wie Sand am Meer gibt, die alle unterschiedliche Aufgaben erfüllen und dabei mal mehr mal weniger gut sind? Oder sprechen wir von KI als „Imaginary“, beispielsweise als „AGI“ das, je nachdem, wen man fragt, immer so fünf bis zehn Jahre in der Zukunft liegt?
Beide Begriffe sind auf ihre eigene Art ephemer. Der erste ist bereits veraltet, wenn dieser Text erscheint, und der zweite wird auf absehbare Zeit vage bleiben, und das könnte sich auch so bald nicht ändern.
Wenn ich hier also von „Künstlicher Intelligenz“ spreche, dann meine ich ganz konkret die generative Künstliche Intelligenz, wie sie seit der Vorstellung von ChatGPT im Oktober 2022 in aller Munde ist. Ich will allerdings für diesen Text auch stellenweise das Abenteuer eingehen, die behaupteten Potenziale der Technologie ernstzunehmen, verweise dann aber auch entsprechend auf die spekulative Natur dieser Imaginaries.
Generative KI basiert auf dem schon länger etablierten „Machine Learning“, bei dem künstliche neuronale Netzwerke mit enorm vielen Daten trainiert werden. Eine neue Software-Architektur (das Transformer Modell), als auch der Einsatz bisher unvorstellbarer Datenmengen (Tausende von Gigabyte an Text- und/oder Bilderdaten), sowie viele Millionen Dollar teure Rechenleistung erlauben es nun, allerlei Content zu produzieren, den selbst Experten schwer von menschengemachten Artefakten unterscheiden können.
Seitdem hat der Hype nur noch mehr Schwung bekommen und es werden Ressourcen in Volkswirtschaftsgröße auf die Weiterentwicklung dieser Systeme geworfen, was in einer ungeheuren Beschleunigung der Entwicklung resultiert. Sam Altman sprach bereits davon, dass die nächsten Jahre bis zu 7 Billionen Dollar Investitionen allein in nötige Computerhardware anzustreben seien.
Generative Künstliche Intelligenz ist deswegen ein „moving target“, das seine Fähigkeiten, Features und Kompetenzen in atemberaubenden Tempo ausweitet. Schon jetzt gibt es nur wenig Zweifel an der Nützlichkeit der Technologie, war ChatGPT doch letztes Jahr eine der schnellstwachsenden Apps und wird auch weiterhin rege genutzt. Dennoch sind die Einsatzgebiete noch begrenzt, da diese Systeme alles andere als fehlerfrei und vorhersagbar agieren. Selbst auf denselben Prompt gleicht keine Antwort der anderen und die Systeme „halluzinieren“ am laufenden Band Zahlen, Daten, Personen, Paragraphen und Buchtitel herbei, so dass man den Output nie ungeprüft übernehmen kann, ohne unangenehme Überraschungen zu erleben.
Dennoch spricht einiges für die Technologie. Generative KIs erhöhen die Produktivität von Softwareentwicklern, genauso wie die Produktivität von Schreibtätigkeiten. Sie beschleunigen kommunikative Prozesse, bis dahin, dass sie sie vollkommen automatisieren. Mit KIs können schnell und günstig allerlei Alltagsillustrationen für alle möglichen Zwecke generiert werden, für die man sonst einen Designer benötigte. KIs werden heute immer mehr zum Nachschlagen von Informationen genutzt oder gar zum personalisierten Lernen von komplizierten Zusammenhängen. KIs können erstaunlich gut von vielen Sprachen in andere Sprachen übersetzen. Bereits angekündigt, sollen KIs sogar demnächst selbsttätig Aufgaben erledigen und als „Agents“ etwa eine Reise planen, inklusive Orte recherchieren und die nötigen Tickets und Unterkünfte buchen können. Zudem haben KIs eine kompetenznivellierende Wirkung. Studien zeigen, dass vor allem performanceschwache Arbeitskräfte überdurchschnittlich vom Einsatz von KI profitieren und auch in der Breite der Bevölkerung hilft KI Menschen, die vorher Schwierigkeiten hatten, etwa einen Brief zu formulieren oder sich graphisch auszudrücken. Manche sprechen gar von einer „Demokratisierung“ des Schreibens oder der Gestaltung.
Und da sind wir beim zweiten schwammigen Begriff: der Demokratie. Es gibt etliche Regalmeter von politikwissenschaftlichen Demokratiedefinitionen und Erklärungen. Für unsere Zwecke scheint mir aber vor allem das Framework der Politikwissenschaftler Bruce Bueno de Mesquita und Alastair Smith nützlich, das sie in ihrem Buch Dictator’s Handbook ausbreiten. Zum einen, weil die Theorie sich gut auf Beziehungsnetzwerke anwenden lässt, aber auch, weil sie zynisch und abgeklärt genug ist, um auch auf die Tech-Branche zu passen. Mesquita und Smith vermeiden es, kategoriale Unterschiede zwischen den politischen Systemen zu markieren, sondern versuchen, universelle Regeln der Macht zu formulieren. Eine der zentralsten Prämissen der Theorie ist, dass Machthaber – egal, ob demokratisch oder autokratisch – immer nach Mitteln und Wegen suchen, ihre Macht abzusichern. Eine weitere zentrale Prämisse ist, dass kein Machthaber ohne die Unterstützung von anderen Menschen regieren kann. Die Kunst, an der Macht zu bleiben, besteht also im klugen Management der eigenen Abhängigkeiten.
Dabei unterscheiden Mesquita und Smith zwischen drei Kategorien von Abhängigkeitsbeziehungen: Das „nominelle Selektorat“ ist die austauschbare Verschiebemasse an Menschen, die selbst über keine Hebel der Macht verfügen. Über ihre Köpfe wird hinweg regiert. Daneben gibt es das „tatsächliche Selektorat“. Das ist eine deutlich kleinere Gruppe, die es zu überzeugen gilt, um an die Macht zu kommen und dort zu bleiben. In der US-Demokratie sind das zum Beispiel die Wähler der Swing-States, in Deutschland wichtige gesellschaftliche Gruppen wie die Rentner oder Autofahrer, also alle Gruppen, die bei Wahlen den Ausschlag geben können. Und schließlich gibt es noch die „gewinnende Koalition“, jene sehr kleine Gruppe, von deren Unterstützung ein Machthaber direkt abhängig ist. Das können zum Beispiel Parteifunktionäre oder potente Geldgeber sein, es können auch einfach Menschen in wirtschaftlichen oder publizistischen Machtpositionen sein. Dieser Gruppe gilt der Großteil der Aufmerksamkeit jedes Machthabers.
Politische Systeme unterscheiden sich nun darin, wie es ihnen gelingt, Machthaber von einer möglichst großen, diversen Gruppe von Menschen abhängig zu halten (Demokratie), oder inwiefern es Machthabern gelingt, ihre Abhängigkeiten möglichst auf die „gewinnende Koalition“ zu reduzieren, die sie dann auf Kosten der anderen beiden Gruppen alimentieren können (Autokratie).
Dabei sind rechtliche Rahmenbedingungen und eingespielte Erwartungen letztlich weniger wichtig als handfeste ökonomisch-materielle Abhängigkeiten. Das OpenAI-Board hatte rechtlich gesehen die Rolle der „gewinnenden Koalition“, doch Sam Altman wusste genau, dass die „Governance Struktur“ nur ein Zettel mit Buchstaben ist und dass die eigentliche Macht im Wissen und den Kompetenzen der Mitarbeiter (dem tatsächlichen Selektorat) sowie im Zugang zu den gigantischen Rechenressourcen von Microsoft (der eigentlichen gewinnenden Koalition) liegen. Indem er beides auf die eigene Seite zog, herrschte das Board nur noch über eine leere Hülle.
So viel zur Theorie. Doch bevor wir über Demokratie und Künstliche Intelligenz reden, lohnt es sich, zunächst einmal abzuschweifen und sich anzuschauen, was passierte, als das letzte Mal eine Technologie unser aller Leben zum Guten wenden sollte: Das Internet.
Das Internet und die Demokratisierung der Öffentlichkeit
Als im März 1991 das Internet zur kommerziellen Nutzung freigegeben wurde, brach für die Welt eine neue Ära an. Vorher waren nur Universitäten, ein paar Regierungsorganisationen und Großkonzerne ans Internet angeschlossen, und seine Nutzung war hauptsächlich wissenschaftlicher Natur. Es war, als wäre der Welt ein riesiges Geschenk gemacht worden. Eine offene und freie Infrastruktur, damals noch vergleichsweise frei von kommerziellen Zwängen, eröffnete unendliche kommunikative und publizistische Freiheiten. Über die 1990er Jahre bildeten sich Informationsangebote, Communities, neue kulturelle Praktiken und Ausdrucksweisen, und eine ganz neue, sich stetig weiterentwickelnde Kultur entstand. Das Internet sei „der neue Ort des Bewusstseins“, verkündete John Perry Barlow in seiner berühmten Unabhängigkeitserklärung des Cyberspace, einem Text, der wie kein anderer versuchte, den enormen Umbruch in seinem ganzen Pathos zu erfassen. Doch um zu verstehen, was für ein tiefer Einschnitt das Internet für die Menschen war, muss man zunächst verstehen, wie Welt vor dem Internet funktionierte.
Am 5. März 1965 schrieb der Journalist und Herausgeber Paul Sethe einen Leserbrief an den Spiegel, in dem er einen Satz fallen lassen sollte, der zu einem geflügelten Wort in der zweiten Hälfte des 20. Jahrhunderts werden würde: „Die Pressefreiheit ist die Freiheit von zweihundert reichen Leuten, ihre Meinung zu verbreiten.“
Die Presse war im zwanzigsten Jahrhundert ein Eliteorgan, und obwohl Presse- und Meinungsfreiheit vom Grundgesetz garantierte Rechte waren, hatten nur sehr, sehr wenige Menschen überhaupt die Möglichkeit, sich öffentlich am Diskurs zu beteiligen. Selbst Sethe, ein bekannter und einflussreicher Journalist, griff zum Leserbrief als Mittel der Meinungsäußerung.
Die Hoffnungen, die sich mit dem Internet verbanden, waren nicht völlig naiv, wenn man sie an den damaligen Strukturen misst. In den letzten zwanzig Jahren hat sich das Internet im Allgemeinen und die Social Media Plattformen im Besonderen zum öffentlichen Marktplatz der Weltgesellschaft entwickelt. Hier werden News konsumiert und sofort rege diskutiert, hier wenden sich Experten unvermittelt ans Publikum, hier werden Proteste organisiert und ausgetragen, hier veröffentlichen Politiker ihre politischen Botschaften, statt wie bisher als Pressemitteilung. Was im Internet wichtig ist, kann von den klassischen Medien nicht ignoriert werden, und wenn Journalisten wissen wollen, wie „die Öffentlichkeit“ über ein Thema denkt, machen sie keine Straßenumfragen mehr, sondern lesen Tweets oder suchen bei Tiktok. Ja, das Internet demokratisierte die Öffentlichkeit, zumindest eine gewisse Zeit lang.
Enshittification
Doch wenn man die heutige Situation genauer betrachtet, kommt man nicht umhin, sich zu fragen, ob das Geschenk des Internets vergiftet war. Internet-Plattformen haben alle Bereiche unseres Lebens durchdrungen, uns in immer tiefere Abhängigkeiten verstrickt und nutzen diese Macht nun immer spürbarer aus. Sie schließen Zugänge, verteuern Services, verschlechtern absichtlich Features und erhöhen Schlagzahl und Länge von Werbeeinblendungen, die darüber hinaus immer weniger als solche erkennbar gemacht werden. „Enshittification“ ist das Wort der Stunde. Der Science-Fiction-Autor und Netzaktivist Cory Doctorow beschreibt damit einen Prozess des mutwilligen kommerziellen Vandalismus der Plattformen an sich selbst, der aus dem Zwang für die Plattformunternehmen motiviert ist, wachsende Renditen bei abgeflauten Nutzerwachstum zu liefern. Der Mechanismus läuft so, dass im ersten Schritt Geschäftskunden und Nutzer zum gegenseitigen Vorteil zusammengebracht werden, im zweiten Schritt wird dann der dadurch entstandene Mehrwert bei den Geschäftskunden (Uberfahrer, Shopbetreiber auf Amazon Marketplace, Werbekunden bei Google und Facebook) durch immer schlechtere, ausbeuterische Konditionen abgeschöpft, bis dann im dritten Schritt der Mehrwert auch bei den Nutzern immer stärker abgeschöpft wird, indem der Service teurer und schlechter gemacht wird. Am Ende landet der komplette Mehrwert der Plattform als Rendite bei den Aktionären.
Herrschte im klassischen Kapitalismus, wer über „die Produktionsmittel“ verfügte, so ist es im digitalen Kapitalismus derjenige, der über die „Mittel der Verbindung“ verfügt. Plattformen haben sich erfolgreich zwischen Shop und Kunden, zwischen Fahrer und Fahrgäste und Informationslieferant und Newsjunkies gequetscht und kassieren nun auf beiden Seiten Wegzoll.
Doch der abgeschöpfte Mehrwert beschränkt sich längst nicht mehr nur auf das Kommerzielle. Silicon Valley hat unsere öffentliche Sphäre in Beschlag genommen und sitzt jetzt an den subtilen Schalthebeln der algorithmisierten Sichtbarkeit von Informationen und Meinungen und exerziert damit immer ungenierter politische Macht. Elon Musk, der letztes Jahr Twitter übernommen hatte, transformiert die Plattform von der wichtigsten digitalen Öffentlichkeit zu einer Nazipropagandawaffe, indem er gezielt Rechtsradikale auf die Plattform holt, Journalisten zensiert, gerichtliche Verfahren gehen NGOs führt und den Empfehlungsalgorithmus auf seine eigenen Posts hin optimiert, mit denen er Verschwörungstheorien über den „Woke Mindvirus“ und den „Great Replacement“ an sein Millionenpublikum promotet.
Macht und Abhängigkeit von Plattformen
Paul Sethe schrieb in dem oben erwähnten Leserbrief weiter: „Da die Herstellung von Zeitungen und Zeitschriften immer größeres Kapital erfordert, wird der Kreis der Personen, die Presseorgane herausgeben, immer kleiner. Damit wird unsere Abhängigkeit immer größer und immer gefährlicher.“
Und hier kommen wir zurück zum Framework von Mesquita und Smith. Ein Machthaber ist immer von anderen abhängig, um seine Macht abzusichern, und hat Anlass, den Kreis seiner Abhängigkeiten möglichst gering zu halten. Vereinfacht ausgedrückt: Ein paar Hundert mächtige Oligarchen (gewinnende Koalition) bei Laune zu halten ist sehr viel einfacher und zuverlässiger zu bewerkstelligen als ein ganzes Volk (nominelles Selektorat), weswegen es rational ist, das Volk zugunsten der Oligarchen auszubeuten. Das bedeutet nicht, dass jeder Machthaber so handelt, aber es bedeutet, dass viele so handeln, sobald sie die Möglichkeit dazu bekommen.
Wie Sethe richtig bemerkt, wird dieser Prozess sehr von ökonomisch-materiellen Abhängigkeiten beeinflusst. In einer hochgradig arbeitsteiligen Gesellschaft existieren enorm viele kleinteilige, weit verstreute Abhängigkeiten, was es schwierig macht, Macht an einer einzigen Stelle zu konzentrieren. Komplexe, arbeitsteilige Gesellschaften mit hohem Spezialisierungsgrad sind deswegen gegen die Machtergreifung eines Autokraten besser gefeit, denn der Autokrat müsste, um die Gesellschaft am Laufen zu halten, sehr viele Leute auf seine Seite ziehen. In Gesellschaften, die weniger ausdifferenzierte Arbeitsteilung haben, zum Beispiel, weil sie ihr Bruttonationaleinkommen zu einem Gutteil aus dem Export von Rohstoffen verdienen, ist dagegen der Kreis an mächtigen Leuten klein und überschaubar, was dem Machthaber ein leichtes Spiel ermöglicht. Ein Umstand, der in der politikwissenschaftlichen Literatur auch als „Ressourcenfluch“ beschrieben wird.
Etwas Ähnliches beschreibt Sethe für die Presseverlage im zwanzigsten Jahrhundert. Kapitalakkumulation und Skaleneffekte bilden die materielle Basis von sich zunehmend konzentrierenden Abhängigkeiten, die dann im 20sten Jahrhundert zu den zweihundert reichen Leuten führt, die ihre Meinung kundtun dürfen. Und es ist ebenfalls genau das, was die letzten Jahre im Internet passiert ist. Doch im Internet kommen zu den oben genannten Effekten noch die sogenannten „Netzwerkeffekte“ hinzu.
Netzwerkeffekte machen einen Dienst immer attraktiver, je mehr andere Menschen daran teilnehmen. Leute locken andere Leute auf die Plattform und halten sie dort. Hat man einmal seine Beziehungen auf einer Plattform etabliert, fällt es schwer, sie auf andere Kommunikationskanäle umzusiedeln oder zu reproduzieren. Dieser „LockIn“ genannte Effekt macht die einmal auf einer Plattform angesiedelten Nutzer zu einer fast beliebig steuerbaren Masse, was – wie wir von Mesquita und Smith wissen – eine stabile Machtkonzentration an der Spitze erlaubt.
Wenden wir das Dictator’s Handbook auf Plattformen an, wird deutlich, wie das Feld der Abhängigkeiten das Handeln der Plattformunternehmen bestimmt und wie das den Prozess der Enshittification präzise erklärt. In einer frühen Wachstumsphase ist eine Plattform stark auf Zuspruch der Nutzer und Geschäftskunden angewiesen, weswegen sie für die Plattform als „tatsächliches Selektorat“ gilt, dem versucht wird, einen möglichst spürbaren Mehrwert zu bieten. Doch sobald die Wachstumsphase vorbei ist und die Nutzer durch den LockIn-Effekt sowieso an die Plattform gebunden sind, wird ihnen ihre Rolle als lediglich „nominelles Selektorat“ zugewiesen, das zugunsten der Aktionäre (also der „gewinnenden Koalition“) immer stärker ausgebeutet werden kann.
Die Konzentrationsprozesse, die Sethe für die Presseverlagslandschaft beschreibt, hat das Internet im Eiltempo durchgespielt. Es ist in wenigen Jahren von einem Ort der dezentralen und offenen Kommunikation, der niemandem gehörte und in dem alle Informationen gleich behandelt wurden, zu einem Spielball von einer Handvoll Konzernen und Milliardären geworden, die nun von den Plattformen zugunsten weniger Kapitalanleger ausgebeutet werden.
Die Graphnahme durch das Silicon Valley
In meinem Buch Die Macht der Plattformen hatte ich diesen Prozess „Graphnahme“ genannt. Wie die Landnahme bei Carl Schmitt ist die Graphnahme eine ursprüngliche, gewaltsame Aneignung, aber eben nicht von Land, sondern von Beziehungen oder etablierten Interaktionszusammenhängen. Ihre Eroberung besteht darin, diese Interaktionen auf die Plattform zu lenken und in den dortigen Datenbanken abzubilden. Das erhöht zum einen den Komfort und weitet die Interaktionsmöglichkeiten für die Nutzer aus, erlaubt der Plattform aber zum anderen auch, eine enorme Kontrolle über diese Beziehungen auszuüben. Wie die Landnahme errichtet auch die Graphnahme ein eigenes Regime.
Seit dem Aufstieg der Plattformen als neues Paradigma sozialer Organisation hat Facebook den „Social Graph“, Google den „Interest Graph“, Amazon den „Consumption Graph“ und Tiktok den „Entertainment Graph“ unter ihre Kontrolle gebracht. Fast alle von uns leben seither unter ihren AGBs und Moderationsregeln und bekommen unsere Informationen entsprechend ihrer algorithmischen Sichtbarkeitsregimes verabreicht. So viel zur Demokratisierung der Öffentlichkeit.
Diese enorme Machtkonzentration im Silicon Valley hat bereits einige Beobachter dazu verleitet von einem neuen Feudalismus zu sprechen. Die Plattformen haben eine ökonomisch-materielle Stellung in der Gesellschaft erlangt, die ihnen weitestgehend von Leistungen unabhängige Renten beschert und die zu einer Kultur des Größenwahns geführt hat. Allein während der Pandemie haben sich die Vermögen der Silicon Valley Milliardäre vervielfacht, und diese enormen Ressourcen haben nicht nur zu abstrusen Abenteuern wie dem Twitterkauf durch Elon Musk, sondern vielerorts auch zu einem zunehmenden Abdriften in ideologische Abgründe geführt.
Elon Musks öffentliche Kernschmelzen und seine zunehmend unverhohlene Sympathie mit rechtsradikalen Verrschwörungstheorien sind dabei nur das sichtbarste Beispiel einer außer Kontrolle geratenen Elite. Silicon Valley CEOs und „Venture Capitalists“ wie Reid Hoffman (LinkedIn), Peter Thiel (Palantir), Sam Altman (OpenAI) und viele andere hängen abstrusen Theorien und ethischen Frameworks an, wie „Effective Altruism“, „Longtermism“ oder „Effective Accelerationism“. In diesen Theorien wird eine unabwendbare Zukunft imaginiert, in der wir als Menschheit unsere Intelligenz und unser Bewusstsein billionenfach ins ganze Universum tragen. Diese Zukunft wird dabei als unvermeidlich und gleichzeitig als dringend anzustreben vorausgesetzt und dient als normative Folie, um alle Handlungen im Hier und Jetzt danach zu beurteilen, ob sie dieser Zukunft zu- (gut) oder abträglich (böse) sind. Das Motto ist „Grow or die“.
Mit der kaltschnäuzigen Selbstsicherheit von Sektengurus glauben die Tech-Milliardäre, die Menschheit in eine Zukunft kommandieren zu dürfen, die sie als Kind in Science-Fiction-Romanen gelesen haben und von der ihnen entgangen ist, dass sie als Warnung formuliert waren. Sie merken dabei nicht einmal, dass das genau sie zu den Bösewichten unserer heutigen Cyberpunk-Welt macht. Diese Menschen sind gefährlich.
Die Graphnahmen der KI
In dieser bereits unvorteilhaften Gemengelage kommt nun die generative KI ins Spiel und beschleunigt die Machtkonzentration noch mal enorm. Auch KI kann als Graphnahme verstanden werden, und sie wird alles in den Schatten stellen, was wir bisher gesehen haben. Genaugenommen handelt es sich um vier Graphnahmen, die uns jetzt drohen.
Die Graphnahme der KI-Technologie
KI-Forschung war bis vor kurzem ein heterogenes Feld, das von Universitäten bis zu kleinen Startups ein vielfältiges Ökosystem bildete. Doch die Möglichkeit, mächtige KIs zu trainieren und bereitzustellen, ist direkt an die Verfügbarkeit von roher Rechenpower gekoppelt, die heute vor allem auf der Verfügbarkeit spezieller Grafikprozessoren basiert und um deren knappe Ressource ein regelrechter Verteilungskampf entbrannt ist. Die ökonomisch-materielle Eigenheit der Künstlichen Intelligenz konzentriert also alle Abhängigkeiten auf die Ebene der Infrastruktur, wo zig Millionen Grafikkarten in Serverclustern die riesigen Datenmengen durchwalten. Alleine dieser Umstand resultiert in einer Machtkonzentration, die selbst die der Plattformen in den Schatten stellt. Die Universitäten sind längst raus aus dem Spiel, und immer häufiger müssen auch die Startups das Handtuch werden. Wer nicht direkt verbandelt mit den digitalen Cloudanbietern wie Microsoft, Google und Amazon, hat keine Chance mehr, was Letzteren die monopolartige Kontrolle über diese Technologie in die Hände legt.
Die Graphnahme des Internets
KI ist hier, um das Internet zu ersetzen. Die Graphnahme des Internets ist bereits im Gange und erfolgt in drei Schritten:
Die Modelle wurden mehr oder weniger mit den Daten des Internets trainiert, urheberrechtlich geschützte Werke inklusive. Viele setzen nun ihre Hoffnung auf eine Handvoll noch laufende Urheberrechtsklagen, doch die historische Erfahrung mit den Plattformen zeigt, wie sie zunächst das Patentrecht und zunehmend das Urheberrecht für sich dazu nutzen, ihre Macht zu konsolidieren. Rechteabtretung ist am Ende eine Frage des Preises und Geld haben die Techfirmen genug. Eine Art, über die Modelle nachzudenken, ist, sie als eine hochkomprimierte Kopie des Internets zu betrachten.
Startups wie Arc Browser oder Perplexity Search verweisen auf ein neues „Search“-Paradigma, bei dem man statt einer Link-Liste direkte Antworten bekommt, die die KI im Hintergrund recherchiert. Diese Antworten sind weniger reichhaltig als eine klassische Ergebnisliste, jedoch auch bequemer, und sie bedienen das Informationsbedürfnis viel direkter. Auch Google bewegt sich immer stärker in diese Richtung.
Weil KI-Modelle weiterhin notorisch unzuverlässig sind, werden sie heute überproportional zur Produktion von Spam und Propaganda eingesetzt, denn da ist die Fehlerhaftigkeit des Outputs vergleichsweise egal. Das führt dazu, dass das Internet und die Social-Media-Plattformen gerade in einem Tsunami von Spam- und Fake-Websites und -Profilen ertrinken. Manche sprechen bereits davon, dass das Informationszeitalter vom Zeitalter des Rauschens abgelöst wurde.
Im Ergebnis führt das dazu, dass die Ersetzung des Internets als Ort der Informationssuche durch die ärmere KI-Variante dadurch abgesichert wird, dass der Weg zurück zum ursprünglichen Internet versperrt ist, weil die generativen KIs es in atemberaubendem Tempo unbrauchbar gemacht haben.
Schon der Machtzuwachs bei den Plattformen war davon getrieben, dass sie ständig Probleme generierten, die nur sie im Stande waren, zu lösen. Und mit KI beschleunigt sich dieser Prozess dramatisch und damit die Abhängigkeit der Weltgesellschaft von den Techriesen.
Die Graphnahme der Sprache und unserer bildlichen Semantik
Die Millionen Texte und Bilder, mit denen die Modelle in der Trainingsphase gefüttert wurden, bilden die grundlegende Semantik unserer Kultur und Gesellschaft ab. GPTs und Diffusion-Modelle machen unsere Kultur nun statistisch operationalisierbar und damit in Annäherung reproduzierbar. Dabei funktionieren diese Modelle so, dass sie aus den Trainingsdaten einen tausenddimensionalen statistischen Vektorraum für alle Beziehungen und Metabeziehungen von Begriffen bzw. Formen extrahieren, der dann für die „Next Word Prediction“ oder Bildgenerierung genutzt werden kann. Mit anderen Worten: Die Modelle synthetisieren die kulturelle Semantik der Gesellschaft.
Werden diese Modelle aber nun von vielen Menschen im großen Maßstab genutzt, um Texte und Bilder halb- oder sogar ganz automatisiert zu erstellen und zu verbreiten, dann erlaubt das den Betreibern eine subtile Kontrolle über Sprache und Semantik. Mit der Kontrolle eines populären Sprachmodells verfügt man über eine Art Massen-Sprechakt-Waffe, mit der man eigene politische Framings, argumentative Figuren und Narrative im großen Maßstab in die generierten Texte und so in den Sprachgebrauch injizieren und so zu ihrer Normalisierung beitragen kann.
Die Graphnahme der Demokratie
Die Transformation durch generative KI setzt sich bis in die Tiefe der gesellschaftlichen Abhängigkeitsstrukturen fort. Schon jetzt sinken die Abhängigkeiten beispielsweise gegenüber den Leistungen von Übersetzern, Grafikern, Programmierern und Textern, und mit zunehmender Mächtigkeit der Modelle werden immer mehr Kompetenzen und Berufsfelder ihre Verhandlungsmacht einbüßen. Nimmt man die Ziele und Prognosen der KI-Unternehmen ernst, dann muss man davon ausgehen, dass sich die arbeitsteilige, funktional differenzierte Gesellschaft in den nächsten Jahren komplett entflechten wird. In der Öffentlichkeit wird in dieser Hinsicht immer nur von den möglichen oder tatsächlichen Arbeitsplatzverlusten geredet – es wird aber nicht thematisiert, dass diese reduzierten Abhängigkeiten durch eine entsprechend erhöhte Abhängigkeit von den Tech-Unternehmen erkauft wird. Alle Macht, so scheint es, konzentriert sich gerade im Silicon Valley.
Innerhalb des Frameworks von Mesquita und Smith ergibt dieses Handeln sowohl für Arbeitgeber als auch für die KI-Unternehmen absolut Sinn: Hier werden breite und vielfältige Abhängigkeiten von Vielen durch eine konzentrierte Abhängigkeit von Wenigen ersetzt, was beiden Akteuren ihre Macht sichert und einfacher managebar macht. Es ist wie eine Verschwörung der KI-Unternehmen mit den Kapitalisten weltweit, um den Menschen aus allen Abhängigkeitsgleichungen zu streichen und ihn so endgültig zu einer macht- und einflusslosen Verschiebemasse zu machen (nominelles Selektorat). Adieu freies Internet. Adieu lebendige, dezentrale Semantik. Adieu komplexe, arbeitsteilige Gesellschaft. Adieu Demokratie.
Der Aufstand?
All das, was ich hier beschrieben habe, wirkt für die meisten Menschen noch fern und abstrakt. Würden sie begreifen, was gerade in atemberaubendem Tempo passiert und wie sich das auf ihre Stellung in der Gesellschaft auswirken wird, würden sie in Massen auf die Straßen strömen.
Vielleicht werden sie das auch noch tun, sobald die Auswirkungen für sie spürbar werden. Noch haben die meisten Menschen, die diese Umwälzung betrifft, vergleichsweise mächtige gesellschaftliche Hebel. Und mit dem Streik der Drehbuchautoren in Hollywood gibt es bereits ein Beispiel, an dem man sich orientieren kann. Ich kann mir durchaus eine weltweite Protestbewegung gegen KI vorstellen. Boykottmaßnahmen, Massendemonstrationen, politischer Druck auf Wirtschaft und Politik, die Systeme zu meiden, zu regulieren oder gar zu verbieten. Ich würde das durchaus begrüßen, aber ich fürchte, eine solche Stoßrichtung wird im Sand verlaufen.
Ich bin skeptisch, dass es gelingen kann, eine offensichtlich so brauchbare Technologie, die bereits jetzt zu einem Großteil als Open Source weiterentwickelt wird, wirksam zu verbieten. Ich glaube deswegen, dass es sinnvoller ist, die Machtstrukturen direkt anzugehen. Von Mesquita und Smith können wir lernen, wie die Konzentration von Macht in der Gesellschaft diese für die Machtergreifung von Autokraten anfällig macht und dass das beste Mittel dagegen ist, die Abhängigkeiten wieder zu dezentrieren.
Das stellt uns nicht nur vor die schwierige Aufgabe, das Silicon Valley zu entmachten und die KI-Systeme unter demokratische Kontrolle zu stellen. Die eigentliche Mammutaufgabe ist, die Gesellschaft wieder so zu organisieren, dass sich die ökonomisch-materiellen Abhängigkeiten weitläufig und kleinteilig über die Menschen verteilen. Und wir haben leider auch nicht den Luxus, auf die dafür zu entwickelnden Gesellschaftsutopien zu warten. Wir müssen jetzt handeln.
Strategisch scheint mir deswegen eine Konzentration nicht auf die Technologie, sondern auf die Ungleichheit am effektivsten. Das herausragendste Symptom der Ungleichheit ist die Existenz von Milliardären. Es braucht ein weltweites Bewusstsein für die Gefahr, die von diesen Menschen für Demokratie und Menschenrechte ausgeht. Die Existenz von Milliardären muss als Politikversagen verstanden werden, und es muss zu einer weltweiten Bewegung kommen, die die Gesellschaft wieder aus den Händen dieser Leute befreit.
Ich gebe zu, dass ich auch hier pessimistisch bin. Im derzeit noch hegemonialen neoliberalen Paradigma gelten Milliardäre lediglich als besonders erfolgreiche Individuen, denen man ihren Reichtum doch einfach gönnen sollte. Es wird nicht gesehen, wie diese Menschen längst das politische Heft in die Hand genommen haben und die Demokratie ihnen bereits vielerorts ausgeliefert ist. Es wird zudem nicht gesehen, wie sich die Machtakkumulation an der Spitze der Gesellschaft gerade enorm beschleunigt, so dass auch unsere Chancen mit jedem Tag schwinden, ihrem Machthunger Grenzen zu setzen können.
Deswegen wäre eine weitere Hoffnung, dass es irgendwie gelingt, die Befürchtungen, die ich in diesem Text so abstrakt und theoretisch formuliert habe, in publikumswirksamere Narrative zu übersetzen, um ein Bewusstsein für diesen gerade stattfindenden Coup in die Breite der Gesellschaft zu tragen
Elon Musk hat nun die Veröffentlichung des Chatbots „Grok“ angekündigt und es scheint tatsächlich so schlimm zu werden, wie ich es mir dachte. In meiner Studie zu Large Language Models hatte ich in einem extra angehängten Epilog genau dieses Szenario antizipiert. Aus aktuellem Anlass veröffentliche ich diesen Abschnitt nochmal gesondert.
Epilog
Die öffentliche Debatte um Künstliche Intelligenz geht sehr häufig um spekulative Szenarien rund um AGI, Superintelligenzen und die Frage, ob diese uns nun retten oder ausrotten werden. Doch LLMs müssen nicht superintelligent sein – eigentlich müssen sie überhaupt nicht in einem menschlichen Sinne intelligent sein –, um einen enormen Einfluss auf alle Aspekte unserer Welt zu haben.
Wenn eine Technologie so tief in unser kollektives Betriebssystem – die Sprache – implementiert wird, sind die Effekte vorhersehbar groß und unvorhersehbar vielfältig. Paul Virilio hat einmal gesagt, dass jede Technologie ihren eigenen Unfall produziert (Virilio/Lotringer 1983, S. 35 f.). Zwei Dinge sind dabei zu ergänzen: Ein Unfall ist nur dann ein Unfall, wenn er nicht vorhergesehen wurde. Und die Gefährlichkeit des Unfalls ist proportional zur Mächtigkeit des verunfallenden Systems. Denken wir an Social Media. Die Euphorie aus den Anfangstagen war im Nu verflogen, als wir feststellten, dass Plattformen als politische Waffen missbraucht werden können. Etwas sehr Ähnliches ist auch für LLMs zu erwarten.
Während diese Studie verfasst wurde, hat sich Elon Musk ausführlich über sein eigenes, geplantes LLM-Projekt namens xAI geäußert (Kerner 2023). Ob es jemals Realität wird, muss wie jede Ankündigung von Elon Musk in Zweifel gezogen werden (Molloy 2023). Dennoch lohnt es sich, die Rhetorik seiner Ankündigungen genauer zu betrachten. Musk spricht z.B. davon, dass sein LLM vor allem der „Wahrheit“ verpflichtet sein werde. Das hört sich erstmal gut an, denn die Wahrheit ist uns schließlich allen wichtig.
Nach allem, was wir in dieser Studie über LLMs gelernt haben, sollte uns diese Ankündigung aber auch sofort misstrauisch machen. LLMs sind strukturell nicht in der Lage, zwischen Wahrheit und Fiktion zu unterscheiden. Sie produzieren immer nur richtig ausschauende Antworten, die zwar häufig wahr sein können, aber nicht müssen. Auch wenn es wahrscheinlich Möglichkeiten gibt, dieses „Halluzinieren“ zu vermindern, ist der Anspruch eine „Wahrheits“-KI bauen zu wollen, ein enorm gefährlicher.
Schaut man weiter im Text, wird auch klar, was Musk genau meint. Seiner Ansicht nach müsse ein LLM von jeder „political correctness“ befreit werden, damit es fähig sei, auch „kontroverse Wahrheiten“ auszusprechen. Man muss das gar nicht in den Kontext seiner vielen rassistischen, sexistischen, transund homophoben und antisemitischen Äußerungen der letzten Jahre betrachten, um zu verstehen, was er damit sagen will. Es reicht, sich anzuschauen, wie er Twitter (mittlerweile „X“) führt und warum er es überhaupt gekauft hat. Twitter, die öffentlichste Bühne unter den Internetplattformen, ist für Musk vor allem eine wichtigste Waffe im Kulturkampf geworden (Seemann 2023). xAI, wenn es je das Licht der Welt erblickt, soll einen sehr ähnlichen Zweck erfüllen.
Das Problem ist, dass sein Wunsch einer politisch unkorrekten KI sehr einfach zu erfüllen ist. Tatsächlich muss man viel Arbeit im Fine-Tuning aufwenden, um einem LLM zumindest die schlimmsten rassistischen Ausfälle halbwegs zuverlässig abzutrainieren. Spart man sich diese Arbeit, bekommt man sozusagen eine rassistische, sexistische und homophobe KI ab Werk.
Dafür gibt es ein bekanntes Beispiel. 2016 veröffentlichte Microsoft einen experimentellen Chatbot namens Tay, den es über die API mit Twitternutzer\*innen interagieren ließ. Tay war so konfiguriert, dass es direkt aus den Konversationen mit anderen lernen konnte. Ein Teil der Nutzerschaft auf Twitter nutzte die Gelegenheit, Tay in allerlei Diskussionen über Rasse und Neonazismus zu verwickeln, bis Tay fast nur noch antisemitische, sexistische und rassistische Dinge ausspuckte (Vincent 2016).
Tay galt als eines der schlimmsten PR-Desaster in der jüngeren Microsoft-Geschichte und wurde als warnendes Beispiel verstanden. Elon Musk sieht darin wohl eher ein weiteres Beispiel der Cancel Culture und will mit xAI diese Leerstelle wieder füllen. Wenn seine KI dereinst schwarze Menschen beleidigt oder von der jüdischen Weltverschwörung redet, wird er das nicht als Fehler betrachten, sondern als „die Wahrheit“ deklarieren. Seine große Gefolgschaft an jungen, weißen Männern wird auch diesmal applaudieren.
Noch einmal: Es ist nicht abzusehen, ob das Projekt überhaupt veröffentlicht wird oder ob es so kommen wird wie oben beschrieben. Doch Musks Plan weist auf eine Gefahr hin, die noch zu wenig thematisiert wird: Es ist nicht nur so, dass LLMs die Biases der Menschen übernehmen oder problematische Denkfiguren reproduzieren. Manche Menschen könnten das genauso wollen.
Dass mit Sprache Politik gemacht wird, ist keine Neuigkeit. Jede Verwendung von Sprache ist zumindest auch politisch, reproduziert sie doch unwillkürlich all die Muster, Narrative und Figuren, auf die wir in der Kommunikation unbewusst zurückgreifen. So definiert z.B. jeder Sprachakt immer auch mit, wo die Grenze zwischen dem verläuft, was eine normale, legitime Äußerung ist, und was nicht (vgl. Mackinac Center for Public Policy 2023).
Ein LLM, zumindest wenn es von vielen Menschen im Alltag verwendet wird, ist eine Teilautomatisierung von Aussagen. Es produziert Sprachakte am Fließband, die von Menschen oft ohne viel Reflexion übernommen und weiterverbreitet werden. LLMs können darüber hinaus ganz automatisiert die Kommunikationswege befüllen und tun das bereits. Wenn jemand Interesse daran hat, eine bestimmte Sprachfigur zu etablieren oder eine bestimmte Rhetorik zu normalisieren, dann wäre die Kontrolle über ein populäres LLM enorm praktisch.
So könnte eine mögliche Zukunft von LLMs aussehen: Politisch segregiert nutzen wir das eine, aber nicht das andere LLM, nicht nur um unsere Kommunikation und unsere Arbeitsund Denkprozesse zu beschleunigen, sondern auch um unsere Sicht auf die Welt auszudrücken. Wenden Sie sich deswegen einfach an den einen oder an den anderen Tech-Konzern ihres Vertrauens.
Schaut man sich Phänomene wie QAnon an, ist es sogar leicht vorstellbar, dass sich um bestimmte LLMs ganze politische Bewegungen, vielleicht sogar sektenartige Anhänger\*innen versammeln, die in dem Output der Maschine die Offenbarung einer höheren spirituellen Wahrheit wähnen. Dafür müssten sich LLMs technisch gar nicht weiter entwickeln. Im Gegenteil, ein zu kohärenter Output wäre hier sowieso nur hinderlich. Oder es könnte ganz anders kommen, und es formiert sich eine gesellschaftliche Gegenmacht, die grundlegende Neuausrichtung unserer gesellschaftlichen Kommunikationsstruktur durch einige wenige Internetkonzerne nicht hinzunehmen bereit ist. Es könnte sich ein breiter Widerstand formen, der versucht, über öffentliche Proteste und politische Einflussnahme die Weiterentwicklung von solchen oder ähnlichen KISystemen zu stoppen. Prominente, Politiker\*innen und Institutionen könnten sich selbst verpflichten, diese Systeme zu boykottieren. Es könnten Verbote von KI in bestimmten Bereichen der menschlichen Kommunikation erlassen werden (Geuter 2023); es könnte vielleicht die Technologie selbst verboten und international geächtet werden (Reijers/Maschewski/Nosthoff 2023).
Auch dieses Szenario ist absolut vorstellbar, wenn man bedenkt, dass im Vergleich zu den bisherigen Automatisierungswellen diese Welle eine wirtschaftlich gut aufgestellte, medial kompetente und sozial gut vernetzte Gruppe bedroht.
Auch über die Frage der Arbeitswelt hinaus ist das Thema Large Language Model ein politisches Thema. Es ist ein Missstand, dass es nach wie vor unter vornehmlich technischen Gesichtspunkten verhandelt wird.
Large Language Models (LLMs) sind in aller Munde, aber kaum jemand versteht, wie sie funktionieren. Es gibt einige ganz gute Explainer in englischer Sprache, aber keine wirklich guten in Deutsch (jedenfalls ist mir keiner untergekommen).
Künstliche Intelligenz (KI) ist ein Feld der Informatik, das fast so alt ist wie die Informatik selbst. In der KI geht es darum, Computer dazu zu bringen, auf bestimmte Arten zu agieren, die von Menschen als intelligent empfunden werden. Das schließt unter anderem die Lösung von komplexen Problemen, das selbstständige Lernen von neuen Fähigkeiten und auch die Beherrschung der menschlichen Sprache mit ein.
Künstliche Neuronale Netzwerke (KNN) sind die derzeit meistverwendete Technologie im Feld der KI. KNN bestehen aus künstlichen Neuronen und sind von den neuronalen Netzwerken im Gehirn von Menschen und Tieren inspiriert. KNN werden in einem Prozess namens „Deep Learning“ oder auch „maschinelles Lernen“ mit großen Datenmengen trainiert und erlangen dadurch Fähigkeiten, die schwer wären, durch normale Programmierung herzustellen; etwa das Erkennen von Objekten, Menschen oder Katzen, oder die Fähigkeit, Texte zu generieren, die Texten menschlichen Ursprungs ähneln.
Natural Language Processing (NLP) ist das Feld der KI, das sich dem maschinellen Analysieren, Transformieren und Generieren von natürlicher Sprache widmet.
Large Language Models (LLM) sind Künstliche Intelligenzen, die auf das Gebiet von NLP spezialisiert sind und aufgrund ihrer beachtlichen Fähigkeiten zur aktuell breit geführten Debatte um KI beigetragen haben. LLMs basieren auf KNN und sie stehen im Fokus dieser Literaturstudie.
Generative Pre-Trained Transformer (GPT) sind die derzeit populärsten LLM-Systeme. Die Firma OpenAI hat mit ihrem Chatbot ChatGPT und Modellen wie GPT-4 derzeit den größten Erfolg. Obwohl auch die meisten anderen LLMs technisch zu den GPTs gezählt werden können, verwendet vor allem OpenAI den Begriff für seine Systeme.
Tokens sind in ganze Zahlen umgewandelte Worte oder Wortbestandteile, wobei jedem Wort eine feststehende Zahl zugewiesen ist. Wenn LLMs trainiert werden, müssen die Trainingsdaten in Tokens umgewandelt werden. Wenn LLMs Sprache verarbeiten oder generieren, verarbeiten sie Tokens und generieren Tokens, die am Ende wieder in Worte umgewandelt werden.
Parameter sind die gewichteten Verbindungen zwischen den künstlichen Neuronen in KNN. In den Parametern liegen die Informationen gespeichert, mit denen eine KI, die auf KNN basiert, arbeitet. Die Anzahl der Parameter gibt eine ungefähre Vorstellung von der Größe und Komplexität und damit auch Leistungsfähigkeit einer KI.
Das Kontext-Fenster (Context Window) umfasst bei LLMs den Kontext eines aktuell zu generierenden Wortes. Da LLMs immer nur das nächste Wort vorhersagen, geschieht diese Vorhersage unter Einbezug aller vorher geschrieben Worte (Tokens), inklusive der Eingabe der Nutzer*innen. Das Kontext-Fenster fungiert somit wie der Arbeitsspeicher eines LLM.
OpenAI ist die Firma, die die derzeit erfolgreichsten und bekanntesten LLMs wie GPT-3.5 und GPT-4 über den Chatbot ChatGPT bereitstellt. Sie wurde 2015 als Non-Profit gegründet, um einen offenen und ethischen Ansatz der KI-Entwicklung zu verfolgen, aber agiert seit 2019 als gewinnorientiertes Startup, das mit Investorengeld Produkte entwickelt und seine wichtigsten Technologien geheim hält. Seit dieser Zeit ist es auch operativ und finanziell eng an Microsoft gebunden.
Es werde das nächste Wort
LLMs sagen immer nur das nächste Wort voraus. Das klingt trivial und ein bisschen so, wie die Wortvorschläge beim Nachrichten-Tippen auf dem Smartphone. Der wesentliche Unterschied zu dieser recht einfachen Technologie besteht darin, dass das Smartphone für eine Wortvorhersage nur vom letzten geschriebenen Wort aus rät. LLMs nehmen dagegen die gesamte Sequenz an geschriebenen Worten als Ausgangspunkt für die Vorhersage.1
Es ist leicht, nach dem Wort „Ich“ ein „bin“ vorherzusagen. Aber wie wird das nächste Wort nach dem Satz, den sie gerade lesen, sein? Wie wird der der Absatz, oder der gesamte Text dieser Studie zu Ende gehen? Natürlich unter Berücksichtigung seiner gesamten bisherigen Struktur, seiner Argumente, dem Schreibstil in dem er verfasst ist, sowie den gesamten Kontext des zu behandelten Themas? An dieser Aufgabe kann man nur scheitern. Aber heute scheitern LLMs besser an dieser Aufgabe als viele Menschen.
Doch was heißt „besser“ in diesem Zusammenhang? Das qualitative Urteil, das an Sprachmodelle herangetragen wird, ist eines der Täuschung. Wenn ein LLM gut ist, meinen wir, dass ihre Resultate uns überzeugen könnten, von einem Menschen verfasst zu sein (Natale 2021). Dazu wurde das System mit Millionen von Menschen geschriebenen Texten gefüttert, die es statistisch durchmessen hat, sodass es anhand dieser Statistik die Wahrscheinlichkeit des nächsten Wortes in einem Satz, Absatz oder Text vorhersagen kann.
In diesem Prozess der statistischen Durchforstung endloser Textmengen hat die Maschine „gelernt“, wie Worte sich statistisch zueinander verhalten. Sprache ist vielseitig und komplex, doch in ihr gibt es auch eine ganze Menge Regelmäßigkeiten. Das LLM lernt z.B. schnell die Regel, dass auf ein Subjekt irgendwann ein Prädikat und dann irgendwann ein Objekt folgt. Das LLM lernt Grammatik, ohne, dass ihm jemand die Subjekt-Prädikat-Objekt-Regel explizit einprogrammieren müsste. Syntaktik und Grammatik sind statistisch vergleichsweise leicht abzuleiten; sie sind so einfach, dass wir sie sogar sie in expliziten Regeln aufschreiben konnten.
Es gibt aber auch eine Menge Regeln bzw. Regelmäßigkeiten in der Sprache, die wir bislang noch gar nicht formell festgehalten haben, weil sie so komplex sind. Nehmen wir den Satz: „Die Wirtschaft spaziert Aschenbecher in der Nadel.“ Das ist ein grammatikalisch wohlgeformter Satz, aber er macht keinen Sinn. Wir können zwar erklären, warum dieser Satz keinen Sinn ergibt, aber wir haben keine allgemeinen Regeln dafür, wie man sinnhafte Sätze formt.
Der überraschende Erfolg der LLMs basiert darauf, dass sie auch semantisch korrekte Sätze zu formen imstande sind. Sprachmodelle kamen bislang immer dort an ihre Grenze, wo die Satzkonstruktion ein gewisses Verständnis des Inhalts erfordert. Etwa bei hierarchischen Satzkonstruktionen wie: „Die Schlüssel zum alten, moderigen Schuppen lagen auf dem Tisch“. Es erfordert ein Verständnis des Inhaltes des Satzes, um das Verb „lagen“ (Mehrzahl, Vergangenheitsform) richtig zu bilden, weil es sich auf das weit zurückliegende „Schlüssel“ bezieht (Mahowald et al. 2023).
Es ist rechnerisch leicht, eine Wahrscheinlich für das Wort nach einem anderen Wort zu berechnen. Man nennt solche Wortpaare „2Grams“. Schon deutlich schwieriger wird es, wenn man ein 3Gram berechnen will, d.h. von zwei Worten aus das dritte zu berechnen. Auf einmal hat man zwei abhängige Variablen, die es zu berücksichtigen gilt und mit jedem zusätzlichen Wort steigen die nötigen Rechenoperationen exponentiell.
Nun könnte man sich vorstellen, aus den gesamten Trainingsdaten die vorkommenden n-grams (n steht für die Anzahl der verkoppelten Worte) zu bilden und zu speichern. Man erhielte eine verlustfreie Kopie der Trainingsdaten. Jedoch würde so eine Prozedur schnell die Rechenkapazitäten aller verfügbaren Computer der Welt sprengen.
Was man stattdessen macht, ist das, was man immer macht, wenn die Realität für die Verarbeitung zu komplex ist: Man macht ein Modell. Ein Modell ist immer eine Annäherung an die Realität, die nicht perfekt, aber für bestimmte Zwecke gut genug ist. LLMs können also wortwörtlich als ein Modell der menschlichen Sprache verstanden werden, so wie eine Modelleisenbahn ein Modell einer wirklichen Eisenbahn ist. So wie eine Modelleisenbahn sich bemüht, alle möglichen Details der Eisenbahn abzubilden, so versucht ein LLM alle möglichen Details von Sprache abzubilden, aber ist dabei, wie die Modelleisenbahn, eben nur so gut, wie es die Technik gerade zulässt.
Das hat einige Implikationen. Wären die Trainingsdaten in n-grams gespeichert, wäre ein LLM in der Lage, alle Fakten, Quellen und Zitate der Trainingsdaten Buchstabe für Buchstabe wiederzugeben. Weil ein LLM aber nur ein Modell der Sprache ist, klappt das nur manchmal.
In den Daten klaffen Lücken und das Modell ist besonders kompetent darin, diese Lücken so zu füllen, dass es so aussieht, als seien da gar keine Lücken. So kommt es vor, dass es enorm selbstsicher formulierte Sätze ausgibt, deren Fakten ausgedacht sind und sie beim genauen Hinschauen teils überhaupt keinen Sinn ergeben. Man spricht dann z. B. davon, dass LLMs „halluzinieren“. Was sie aber eigentlich tun, ist die Lücken zu füllen mit Worten, die statistisch plausibel hineinpassen.
Ted Chiang, Autor beim Magazin The New Yorker, brachte diese Modellhaftigkeit der Sprachmodelle gut auf den Punkt, indem er sie mit JPEGs verglich. (Chiang 2023) JPEG ist so etwas wie das Standardformat für Fotos im Internet und ist bekannt für seine enorm effektive, aber verlustreiche Kompression. Speichert man seine Fotos im JPEG-Format, lassen sich eine Menge Daten sparen, doch schaut man genauer auf die Details in den Fotos, fallen einem die verschwommenen Fragmente an den Rändern von Konturen ins Auge. ChatGPT sei ein verschwommenes JPEG des Internets, so der Autor.
JPEGs sind für viele Zwecke ungenügend, vor allem Profis greifen lieber auf verlustfreie Kompressionsformate zurück. Dennoch haben JPEGs einen enormen Nutzen und das gilt offenbar auch für LLMs, zumindest wenn man ihre Stärken und Schwächen kennt. Wie immer gilt der Ausspruch von George Box: „Alle Modelle sind falsch, aber manche sind nützlich.“ (Box 1979, S. 202).
Kontext: Die Deep-Learning-Revolution vor zehn Jahren
Das Training von LLMs ist sehr gradlinig. Man gibt der Maschine einen Teil von einem Text und bittet sie, das nächste Wort zu ergänzen. Dann vergleicht man das geratene Wort mit dem tatsächlich im Text folgenden Wort, errechnet den Fehlerwert und gibt das Ergebnis an das System zurück, das die Information dazu verwendet, seine Vorhersagefähigkeiten zu verbessern. Am Anfang wird die Maschine noch irgendwelche zufälligen Wörter vorschlagen, die nicht mal ansatzweise Sinn ergeben. Etwa „Ich Tasse“ oder „Mensch rot“. Die dadurch ausgelösten negativen Feedbacksignale helfen aber jedes Mal ein kleines Stück, das System zu verbessern. Je öfter das System diesen Prozess durchgemacht hat – wie sprechen hier von Hunderte Milliarden Mal – desto besser wird es im Raten.
Das dahintersteckende Verfahren ist sehr viel älter als die aktuellen Sprachmodelle und nennt sich „Deep Learning“. Beim Deep Learning geht es darum, mittels großer Datenmengen ein künstliches neuronales Netz zu trainieren. KNN sind von natürlichen neuronalen Netzen wie die Gehirnstrukturen von Menschen und Tieren inspiriert.2
Die ersten künstlichen Neuronen im sogenannten „Perceptron“ von 1958 waren tatsächlich noch Hardware-Relais, die mit Drähten verbunden waren (Loiseau 2019). Experimente mit KKN auf Softwarebasis wurden seit den 1970er-Jahren immer wieder gemacht, doch bis auf wenige Einsatzzwecke z. B. in der E-Mail-Spamerkennung hatte der Ansatz nur wenig Relevanz. Erst im Jahr 2012 gelang der Durchbruch. Bis dahin gab es unterschiedliche Ansätze, Künstliche Intelligenz voranzubringen, etwa symbolische Systeme oder Expertensysteme. Bei diesem Ansatz versuchen Menschen die zu lösenden Aufgaben in Form von Regeln zu definieren und diese Regeln als Code im KI-System zu implementieren. Das war noch bis 2010er-Jahre hinein einer der wichtigsten KI-Ansätze.
Das änderte sich mit der „ImageNet Challenge“ von 2012, einem Wettbewerb in künstlicher Bilderkennung. Damals hatte sich das Team unter der Leitung von Geoffrey Hinton mit einem „Deep Neural Net“ (ein anderer Name für KNN) namens AxelNet mit großem Abstand zu allen anderen Bewerbern durchgesetzt. Seitdem dominieren KKN das gesamte Feld von KI und selbstlernender Systeme, nicht nur in der Bilderkennung.
Die künstlichen Neuronen eines KNN sind in mehreren Ebenen („layers“) angeordnet, und zwischen den Ebenen durch künstliche Synapsen miteinander verbunden. Die erste Ebene ist die Input-Ebene, also die Reihe von Neuronen, auf die die eingehenden Daten treffen. Am Ende steht die Output-Ebene, die das Ergebnis der Berechnung liefern soll: ist ein Hund oder Katze auf dem Bild, oder was ist das nächste Wort?
Zwischen Input und Output sind mehrere sogenannte „versteckte Ebenen“ („hidden layers“) geschaltet, die die eigentliche Informationsprozessierung handhaben. Grob gesagt kann ein künstliches Neuronales Netz mit mehr versteckten Ebenen komplexere Aufgaben bewältigen und je mehr versteckte Ebenen es gibt, desto aufwendiger sind die Durchläufe durch das Netz.
Treffen Daten auf die Input-Ebene, entscheiden die einzelnen Neuronen jeweils anhand einer integrierten Funktion, ob und wie stark sie das Signal an die dahinterliegende versteckte Ebene weiterreichen sollen. Die Neuronen der versteckten Ebene haben ebenfalls eine Funktion, um zu entscheiden, wie die eintreffenden Signale der Input-Ebene gedeutet werden sollen und geben davon abhängig ihrerseits ein Signal an die Neuronen der nächsten versteckten Ebene weiter.
Und so wandern die vom Input ausgelösten Signale von Ebene zu Ebene, wobei jedes Neuron von sich aus entscheidet, welchen Output es auf welchen Input hin weitergibt. Je weiter sich die Signale durch die versteckten Ebenen arbeiten, desto abstraktere Informationen werden für gewöhnlich verarbeitet. Hier ein vereinfachtes Beispiel für eine Bilderkennung: Die Input-Ebene bekommt ein Bild und teilt es in Bereiche für ihre Neuronen auf. Die erste versteckte Ebene identifiziert darin Kontraste, die zweite Ebene interpretiert die Kontraste und erkennt Formen, die dritte Ebene fügt die Formen zu einer Gesamtkomposition zusammen und die Output-Ebene gibt Wahrscheinlichkeitswerte aus, welchen Objekten die Gesamtkompo-sition ähnlich sieht. Jeder Input durchläuft das gesamte neuronale Netzwerk, bis es an der Output-Ebene zu einer Entscheidung kommt.3
Befindet sich das neuronale Netz im Trainingsprozess, wird ihm nach jedem Durchlauf zurückgespiegelt, ob es richtig lag. Dieses Feedback wird dann wiederum im ganzen Netzwerk verarbeitet, nur läuft es diesmal rückwärts. Dabei errechnet eine sogenannte „Verlust-Funktion“ (Loss Function), wie weit das Netzwerk vom richtigen Ergebnis entfernt lag.
Bei einer falschen Bilderkennung schaut die Output-Ebene, welche Verbindungen (Parameter), der letzten versteckten Ebene dazu beitrugen, die falsche Entscheidung zu treffen und reduziert ihre Relevanz durch Anpassung der Gewichtungen. Dasselbe tut die versteckte Ebene mit ihrem Vorgänger, und diese wiederum mit ihrem Vorgänger und so weiter, bis hin zur Input-Ebene. Dieses automatische Einarbeiten von Feedback durch das ganze Netz nennt man „Backpropagation“ und ist zentraler Bestandteil aller heutigen KNN, inklusive der LLMs. Dabei steht die Minimierung der Verlust-Funktion im Zentrum. Wenn der errechnete Verlustwert nicht mehr sinkt, ist das Netzwerk im Rahmen der gegebenen Möglichkeiten fertig trainiert.
Dass der Durchbruch dieser Technologie erst im Jahr 2012 erfolgte, obwohl daran seit den 1970er-Jahren geforscht wird, lag an zwei Faktoren: Zum einen können derart signifikante Ergebnisse nur mit einer enormen Menge von Trainingsdaten erzielt werden, so vielen Daten, wie sie vor der massenweisen Verwendung des Internets den Wenigsten zur Verfügung standen.
Der zweite Faktor war, dass das Training eines neuronalen Netzwerks ab einer bestimmten Komplexität enorme Rechenkapazitäten erfordert. Durch die Popularisierung von Videospielen standen ab den 2010er-Jahren leistungsfähige Grafikprozessoren (GPUs) zur Verfügung, die bestimmte Berechnungen schneller als herkömmliche Prozessoren und dazu noch parallel durchführen konnten.
Durch diese beiden Faktoren konnten immer komplexere Modelle mit immer mehr versteckten Ebenen auf noch mehr Daten trainiert werden, und dieses Skalieren von Ebenen, Parametern und Trainingsdaten führt bis heute zu immer neuen Fähigkeiten von KNN.
Der Trainingsprozess: Einbettung im latenten Raum
Auch die heutigen LLMs, basierend auf dem Transformermodell (dazu gleich mehr), müssen trainiert werden. Zuvor müssen allerdings die Trainingsdaten bereitgestellt und bearbeitet werden. LLMs sind mit Billionen von Wörtern trainiert und die müssen erstmal gesammelt werden. Dabei spielt das Internet eine wichtige Rolle. Selbst riesige Textsammlungen wie die Wikipedia oder die Summe aller digitalisierten Bücher machen nur einen Bruchteil der Trainingsdaten aus. Der größte Teil der Texte kommt aus rudimentär gesäuberten Datensammlungen, die im Grunde aus Millionen beliebig zusammengesuchten Websites bestehen.4
In einem zweiten Schritt müssen diese Trainingsdaten für das Modell in Tokens umgewandelt werden. Dafür gibt es sogenannte Tokenizer, also Programme, die jedem Wort oder Wortbestandteil, eine ganze Zahl zuordnen. Mit jedem Token wird dann ein vieldimensionaler Vektor verknüpft – ein sogenanntes „Embedding“ – eine „Einbettung“ in den Kontext aller anderen Tokens. Im Embedding sind alle Beziehungen eines Tokens zu allen anderen Tokens gespeichert. Zu Beginn des Trainings ist dieser Vektor allerdings noch mit rein zufälligen Werten belegt. Wenn das Modell im Laufe des Trainings dann für jede Abfolge von Tokens den jeweils nächsten Token rät, wird die Vorhersage mit dem Ergebnis des tatsächlich nächsten Tokens in den Trainingsdaten verglichen und die Abweichung der Verlust-Funktion per Back-Propagation durch das Netzwerk zurückgefüttert. Im Zuge dieses Lernprozesses werden nicht nur die Verbindungen neu gewichtet, sondern es werden auch mit jedem Schritt die Embeddings der Tokens aktualisiert. Auf diese Art bilden sich im Zuge des Trainings die Beziehungen der Tokens zueinander immer deutlicher heraus.
Am Ende dieses langen Prozesses ist in den Embeddings die Komplexität von sprachlichen Äußerungen nicht nur auf Wort- oder Satzebene, sondern auch auf Konzept- und Ideen-Ebene gespeichert. Es entwickelt sich eine 1000-dimensionale Landkarte (bei GPT-3.5 sind es 12.288 Dimensionen) der Sprache. In dieser Landkarte ist hinterlegt, wie sich „Rot“ zu „Vorhang“ verhält, „Liebe“ zu „Haus“ und „Zitronensäurezyklus“ zu „Salat“. Das Modell kennt diese Dinge nicht aus eigener Anschauung, aber es hat aus den Millionen Texten erfahren, in welche vielfältigen Verhältnisse wir diese Begriffe zueinander setzen.
Diese Landkarte wird auch als „latent space“, als latenter Raum bezeichnet. Im latenten Raum liegen semantisch ähnliche Wörter nahe beieinander und semantisch unähnliche sind weiter entfernt. Ein vereinfachtes Beispiel: Zieht man vom Embedding „König“ das Embedding „Mann“ ab und addiert das Embedding „Frau“, landet man im Latenten Raum beim Embedding „Königin“ (Mikolov et al. 2013).5 LLMs sind kompetent, auf dieser Landkarte zu navigieren. Gibt man z.B. GPT-3.5 einen Textanfang, dann ist das, als hätte man dem Modell einen Pfad auf dieser Landkarte vorgezeichnet und es am Endpunkt des Pfades abgesetzt mit der Aufgabe, ihn selbstständig weiterzugehen. Das ist eine anspruchsvolle Aufgabe, gibt es doch auf jeder der 12.288 Dimensionen Nähen und Fernen zu anderen Tokens (z.B. assoziative Nähen und Fernen, funktionale Nähen und Fernen, phonetische Nähen und Fernen etc.).
Dabei sind zwar alle Tokens des bereits zurückgelegten Weges mit in Betracht zu ziehen, doch der Aufmerksamkeitsmechanismus hat wichtige Wegmarken nochmal gesondert gekennzeichnet, um Orientierung zu geben. Wie ein Pfadfinder sucht GPT-3.5 nun nach möglichst ausgetretenen Pfaden, die mit dem Herkunftspfad und den Orientierungsmarken in Übereinstimmung zu bringen sind. Eine interessante Besonderheit bei LLMs ist, dass man Einfluss nehmen kann, wie ausgetreten die Pfade sein sollen, die das Modell aussucht. Die einfachste Idee wäre, tatsächlich immer das wahrscheinlichste Wort zu nehmen und auszuspucken. Es hat sich jedoch gezeigt, dass die Texte dadurch oft sehr starr und wenig interessant werden und dass sie schnell dazu tendieren, sich zu wiederholen. Deswegen kann man über die „Temperatur“ die „Wildheit“ des Modells einstellen.
Temperatur ist ein Wert, der angibt wie oft das Modell nicht das wahrscheinlichste, sondern auch mal das zweit- oder drittwahrscheinlichste Wort als Vorhersagen verwenden soll. Bei einer Temperatur von 0,1 wird das Modell sehr konsistente, aber langweilige Texte produzieren, bei einer Temperatur von 0,9 kommt kaum mehr verständliches Gerede bei rum. Meist wird deswegen mit einer Temperatur um die 0,7 gearbeitet (Wolfram 2023).
Der Aufstieg der Transformer-Modelle
Seit 2012 haben sich viele unterschiedliche Architekturen für KNNs durchgesetzt. Multilayer Perceptrons (MLP), Convolutional Neural Networks (CNN) und Recurrent Neural Networks (RNN) waren vor den Transformermodellen die populärsten Architekturen. Sie sind heute überall zu finden. In Fotosoftware, Suchalgorithmen, oder auch in der Industrie in den unterschiedlichsten Anwendungen.
Der technologische Durchbruch, der die aktuell erfolgreichen generative KIs wie ChatGPT, aber auch Bildgeneratoren wie Midjourney und Stable Diffusion ermöglicht hat, wurde 2017 durch Forscher*innen bei Google in einem Paper mit dem Titel „Attention Is All You Need“ (Vaswani et al. 2017) beschrieben. In dem Aufsatz wird das sogenannte Transformer-Modell beschrieben. Das ist eine Architektur für KNN, die jeder versteckten Ebene (in diesem Fall heißt sie „Feed-Forward-Ebene“) eine sogenannte Aufmerksamkeits-Ebene zur Seite stellt (Nyandwi 2023). Die soll ihr helfen, den relevanten Kontext der aktuellen Aufgabe besser im Blick zu behalten, indem er den in den Embeddings zusätzlich vermerkt wird.
Aufmerksamkeit ist deswegen wichtig, weil z. B. beim Generieren des nächsten Tokens zwar der ganze Kontext (alles vorher Geschriebene) mit in Betracht gezogen werden muss, aber eben nicht alles gleich stark (Serrano 2023). Um den Satz „Die Schlüssel liegen dort, wo ich sie hingelegt habe.“ zu schreiben, muss das System z. B. beim Generieren des Wortes „sie“ wissen, dass es sich auf „Schlüssel“ bezieht. Das Wort Schlüssel ist in diesem Moment des Generierens von „sie“ also wichtiger als die anderen Worte des Satzes.
Die Aufmerksamkeits-Ebene assistiert der versteckten Ebene, indem sie den jeweiligen Kontext des zu bearbeitenden Tokens nach Relevanz sortiert und entsprechend gewichtet. Für jeden Token im Kontext-Fenster wird die Relevanz jedes anderen Tokens berechnet und diese in seinen Embeddings vermerkt. Das hilft nicht nur dabei, grammatikalische Konsistenz zu erhalten. Die Tokens (und damit die multidimensionalen Embeddings) durchwandern das ganze Netzwerk von Aufmerksamkeits- und Feed-Forward-Ebenen und werden von jeder einzelnen der Aufmerksamkeitsebenen mit neuen Kontexten angereichert, die als neue Dimensionen im jeweiligen Embedding vermerkt werden.
Heutige Modelle haben sehr viele von diesen Ebenen, bei GPT-3.5 sind es über 90. In den tieferliegenden Ebenen, dort wo abstraktere Aspekte prozessiert werden, hilft der Attention-Mechanismus dem Modell unter anderem narrative oder konzeptionelle Kohärenz eines Textes zu gewährleisten (Lee/Trott 2023).
Wenn man z. B. einen Text mit der Hochzeit von Alice und Bob anfängt, „versteht“ das System, dass diese Hochzeit und ihre Protagonisten wichtig für die Fortführung des Textes bleiben und schreibt ihn fort, ohne dabei den thematischen Fokus zu verlieren. Oder wenn man das Modell bittet, eine komplexe Denkaufgabe zu lösen, hilft der Attention-Mechanismus, sich auf die wesentlichen Bestandteile der Antwort zu konzentrieren.
Es stellt sich heraus, dass fokussierte Aufmerksamkeit auf jeder Abstraktionsebene auf unterschiedliche Weise hilfreich ist. Am Ende, wenn das System die Entscheidung darüber trifft, welches nächste Wort nun ausgegeben wird, sind alle bisherigen Tokens des Kontext-Fensters mit abertausenden zusätzlichen kontextbezogenen Dimensionen angereichert, die mit in die Berechnung einbezogen werden.
Die Transformer-Architektur ermöglicht es dem System zudem, die Aufmerksamkeits-Gewichtungen parallel für viele Worte gleichzeitig zu berechnen. Das spart Zeit und erklärt, warum Grafikprozessoren (GPUs) mit vielen Prozessorkernen eine wichtige Ressource für die Entwicklung von aktuellen LLMs darstellen.
Eine weitere Eigenschaft von Transformer-Modellen ist, dass sie nach dem Training noch verfeinert werden können. Nach dem initialen Training erhält man ein sogenanntes „pre-trained model“ oder auch „foundational model“ genannt. Die durch das Pre-Training erworbene Kompetenz im Interpretieren von Sprache kann dann für die Feinabstimmung des Systems genutzt werden. So kann es durch ein sogenanntes „reinforcement learning by human feedback“ auf bestimmte Aufgaben optimiert werden, beispielsweise für Übersetzungsaufgaben, Textanalyse, Recherche oder den Einsatz als Chatbot wie ChatGPT.
Bei OpenAI z. B. geschieht das Reinforcement Learning in zwei Schritten: speziell geschulte Leute werden beschäftigt, um Beispiel-Prompts und dazugehörige „gute“ Antworten zu erstellen, mit denen das System weitertrainiert wird. Dabei werden vergleichsweise wenig Trainingsdaten verwendet, diese sind aber qualitativ hochwertig und werden im Training stärker gewichtet. In einem zweiten Schritt lässt man das Modell nach diesen Vorbildern selbst mehrere Antworten auf einen Prompt generieren und lässt Menschen die beste der Antworten auswählen (Karpathy 2023).
Josh Dzieza bringt die Rolle des Fine-tuning in einem Artikel für die The Verge auf den Punkt: „Anders ausgedrückt, scheint ChatGPT so menschlich zu sein, weil es von einer KI trainiert wurde, die Menschen nachahmte, die wiederum eine KI bewerteten, die Menschen imitierte, die so taten, als wären sie eine bessere Version der KI, die auf menschlichen Texten trainiert wurde.“ (Dzieza 2023).
Literatur
Box, George E. P. (1979): Robustness in the strategy of scientific model building. In: Launer, Robert L. / Wilkinson, Graham N. (Hrsg.): Robustness in Statistics, Cambridge, Mass.: Academic Press, S. 201–236. https://doi.org/10.1016/b978-0-12-438150-6.50018-2 (Abruf am 4.9.2023).
Chiang, Ted (2023): ChatGPT Is a Blurry JPEG of the Web. In: The New Yorker, 9.2.2023. www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web (Abruf am 18.8.2023).
Dertat, Arden (2017): Applied Deep Learning – Part 1: Artificial Neural Networks. In: Towards Data Science, 8.8.2017. https://towardsdatascience.com/applied-deep-learning-part-1-artificial-neural-networks-d7834f67a4f6 (Abruf am 18.8.2023).
Dzieza, Josh (2023): AI Is a Lot of Work. In: The Verge, 20.6.2023. www.theverge.com/features/23764584/ai-artificial-intelligence-data-notation-labor-scale-surge-remotasks-openai-chatbots (Abruf am 18.8.2023).
Karpathy, Andrej (2023): State of GPT. Microsoft Build. https://build.microsoft.com/en-US/sessions/db3f4859-cd30-4445-a0cd-553c3304f8e2 (Abruf am 18.8.2023).
Loiseau, Jean-Christophe B. (2019): Rosenblatt’s perceptron, the first modern neural network. A quick introduction to deep learning for beginners. In: Towards Data Science, 11.3.2019. https://towardsdatascience.com/rosenblatts-perceptron-the-very-first-neural-network-37a3ec09038a (Abruf am 18.8.2023).
Mahowald, Kyle / Ivanova, Anna A. / Blank, Idan A. / Kanwisher, Nancy / Tenenbaum, Joshua B. / Fedorenko, Evelina (2023): Dissociating language and thought in large language models: a cognitive perspective. https://arxiv.org/pdf/2301.06627 (Abruf am 18.8.2023).
Mayo, Benjamin (2023): Apple says it has fixed iPhone autocorrect with iOS 17. In: 9TO5Mac, 5.6.2023. https://9to5mac.com/2023/06/05/ios-17-iphone-autocorrect/ (Abruf am 18.8.2023).
Mikolov, Tomas / Sutskever, Ilya / Chen, Kai / Corrado, Greg / Dean, Jeffrey (2013): Distributed Representations of Words and Phrases and their Compositionality. In: Advances in Neural Information Processing Systems 26, S. 3111–3119.
Nagyfi, Richard (2018): The differences between Artificial and Biological Neural Networks. In: Towards Data Science, 4.9.2018. https://towardsdatascience.com/the-differences-between-artificial-and-biological-neural-networks-a8b46db828b7 (Abruf am 18.8.2023).
Natale, Simone (2021): Deceitful Media. Artificial Intelligence and Social Life after the Turing Test, Oxford: Oxford University Press.
Nyandwi, Jean (2023): The Transformer Blueprint. A Holistic Guide to the Transformer Neural Network Architecture. In: Deep Learning Revision, 29.7.2023. https://deeprevision.github.io/posts/001- transformer/ (Abruf am 18.8.2023).
Saeed, Waddah / Omlin, Christian (2023): Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. In: Knowledge-Based Systems 263. DOI: 10.1016/j.knosys.2023.110273. (Abruf am 18.8.2023).
Schaul, Kevin / Chen, Szu Yu / Tiku, Nitasha (2023): Inside the secret list of websites that make AI like ChatGPT sound smart. In: The Washington Post, 19.4.2023. www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/ (Abruf am 18.8.2023).
Vaswani, Ashish / Shazeer, Noam / Parmar, Niki / Uszkoreit, Jakob / Jones, Llion / Gomez, Aidan N. / Kaiser, Lukasz / Polosukhin, Illia (2017): Attention Is All You Need. https://arxiv.org/abs/1706.03762 (Abruf am 18.8.2023).
Wolfram, Stephen (2023): What Is ChatGPT Doing … and Why Does It Work? https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/ (Abruf am 18.8.2023).
Fußnoten
Dieser Unterschied wird vielleicht nicht mehr lange existieren. Apple hat bereits für sein aktuelles Smartphone-Betriebssystem angekündigt, die Wortvorschläge und Autokorrekturen in Textnachrichten tatsächlich mithilfe eines GPT zu generieren (Mayo 2023). ↩
Zu den tatsächlichen Unterschieden von künstlichen und natürlichen Neuronen siehe Nagyfi 2018. ↩
Das ist, wie gesagt, ein vereinfachtes Beispiel zur Veranschaulichung der ungefähren Verarbeitungsmechanik. In Wirklichkeit ist sie wesentlich komplexer, und Wissen- schaftler*innen haben große Schwierigkeiten, bestimmte Informationsverarbeitungsschritte einem Neuron oder eine Ebene zuzuordnen. Tatsächlich ist die Verarbeitungsmechanik ein eigenes Forschungsfeld (vgl. Saeed/Omlin 2023). ↩
Um einen Eindruck zu bekommen, wie diese Trainingsdaten aufgebaut sind, hat die Washington Post ein populäres Trainingsdaten-Set in einer Infografik aufbereitet (Schaul/Chen/Tiku 2023). ↩
Das Beispiel ist aus dem Vektorraum eines Sprachmodells aus dem Jahr 2013, also vor der Erfindung der Transformer-Modelle, es sollte aber auch für aktuelle Systeme eine ungefähre Gültigkeit haben. ↩
Immer, wenn ich ein Buch über ein Thema geschrieben habe, schläft mein Interesse für das Thema ein bisschen ein. Das ist ja auch verständlich, schließlich habe ich alles, was ich glaube, über das Thema zu sagen zu haben, schon gesagt. Da! Lies nach! Das gilt natürlich auch für das Plattformthema.
Natürlich kann es sein, dass etwas ganz neues passiert, das das bereits Geschriebene in Frage stellt. Das passiert gerade gewissermaßen hinsichtlich der AI-Revolution und da werde ich sicher auch noch mal was drüber machen, aber hier soll es um etwas anderes gehen. Nämlich um den Kampf der Mastodon-Admins gegen Metas Versuche, im Fediverse Fuß zu fassen.
Also, was ist passiert? Nachdem Elon Musk Twitter zu seinem persönlichen „Stürmer“ umfunktioniert hat, gab es mehrere Migrationswellen von Twitteruser*innen zum freien, protokollbasierten Mastodon. Daneben positionieren sich auch viele weitere Wettbewerber und buhlen um die Gunst tatsächlicher und potentieller Twitterexilant*innen. Und während die Welle gen Mastodon inzwischen ziemlich abgeebbt ist und sich eine gewisse Ernüchterung breit macht, setzten große Social Media Konzerne an, ihren Hut in den Ring zu werfen. Darunter Substack, Tumblr, Medium und Meta.
Interessanter Weise kündigten die letzten drei genannten allesamt an, das sogenannte ActivityPub-Protokoll zu implementieren, also das Protokoll, auf dem auch Mastodon basiert. Das bedeutet, dass diese noch zu launchenden Dienste alle in der Theorie mit Mastodon interoperabel wären, dass man also als User einer beliebigen Mastodoninstanz auch Accounts von den großen Playern abonnieren kann und umgekehrt. Die Gesamtheit aller über ActivityPub miteinander interoperablen Instanzen und Dienste nennt man dabei das „Fediverse“.
Die erste, verständliche Reaktion darauf ist natürlich, sich zu freuen. Dem etwas verschlafenen – böse Zungen sagen im eigenen Nerdsaft darbenden – Fediverse könnte so endlich der ersehnte Durchbruch gelingen. ActivityPub könnte tatsächlich zu einem universellen Standard der Social Media Kommunikation werden, so wie das Internet und das WWW ebenfalls als offene Standards die Welt eroberten. Die großen Silos würden aufgebrochen und niemand könnte mehr auf Kosten der Nutzer*innen neue Silos bauen, ohne sich inkompatibel mit dem großen Rest zu machen. Endlich wäre alles frei und offen und alle tanzen mit Blumen im Haar gen Sonnenuntergang.
Aber derzeit sieht die Stimmung auf Mastodon ganz anders aus. Es gibt eine Petition, die sich an Mastodon-Instanz-Admins wendet, sich dem der Umarmung von Meta zu erwehren. Als Mastodon-Admin hat man nämlich die Möglichkeit, andere Instanzen pauschal zu blocken, so dass die eigenen Nutzer*innen eben nicht in der Lage sind, den Nutzer*innen auf der geblockten Instanz zu folgen und es hat sich eine gewisse Unkultur im Fediverse entwickelt, davon aus der Hüfte heraus Gebrauch zu machen. Nicht falsch verstehen: ich bin ein großer Freund des Blockens. Aber auf individueller Ebene. Natürlich gibt es legitime Gründe auch ganze Instanzen zu blocken. Etwa, wenn es sich nur um Spam oder Nazis handelt. Aber häufig wird von dieser nuklearen Option schon gebrauch gemacht, wenn sich irgend ein User gegen einen anderen der eigenen Instanz mal blöd benommen hat. Egal, ich schweife ab.
Jedenfalls gibt es bei den Idealisten des Fediverse eine gewisse, durchaus verständliche Antipathie gegenüber den großen Social Media Unternehmen und dazu die Befürchtung, dass Meta mit seinen Ressourcen und seiner Netzwerkmacht das Fediverse gewissermaßen „übernehmen“ könnte. Das Stichwort ist „embrace, extend, extinguish„. Im Grunde unterstellt man Meta ein Playbook, bei dem es im ersten Schritt den offenen Standard umarmt („embraced“), ihn im Laufe der Zeit propietär mit neuen Features ausweitet („extended“) und schließlich durch Abschottung ausradiert, („extinguished“). Dieses Playbook wurde ende der 1990er Jahre Microsoft im Umgang mit dem WWW, unterstellt. Microsoft „umarmte“ das WWW und integrierte es schnell auf allen Ebenen seiner Produkte. Es schaffte es dazu den mit abstand populärsten Browser, den Internet Explorer, zu etablieren, mit weit über 90% Marktanteil. Und dann weitete Microsoft die Web-Standards unilateral und propietär aus, zum Beispiel durch Active Scripting, um es besser in sein Outlook und Office Paket zu integrieren (was vor allem zu Security-Alpträumen führte).
Es ist also nicht so, dass das ein irreales Szenario ist und dass Meta nicht genau das versuchen könnte. Ich selbst habe in meinem Plattformbuch genau diese Aneignungsstratgien (Ich nenne es Graphnahme) ein ganz eigenes Oberkapitel gegeben. Der „embrace, extend, extinguish“-Ansatz wird bei mir allerdings als „Integrationangriff“ abgehandelt.
„Beim Integrationsangriff geht es darum, den Graphen einer Plattform in die eigene souveräne Plattform zu integrieren, das heißt, ihn unter das eigene Kontrollregime zu bringen. Der Angriff gleicht dem Iterationsangriff, doch während der angegriffene Graph beim Iterationsangriff nur latent ist, ist er beim Integrationsangriff bereits ausgeprägt, und während beim Iterationsangriff die höhere Ebene beim Angriff erst erschaffen wird, ist sie beim Integrationsangriff bereits hegemonial. Das stellt den Angriff unter einige Erfolgsbedingungen: Erstens darf die angegriffene Plattform nicht ihrerseits über ein hohes Maß an Souveränität verfügen, und zweitens muss die Angreiferplattform bereits einen Fuß in der Tür haben und die eigene Hegemonie als Hebel benutzen können, um sie aufzustemmen.“
Die Macht der Plattformen, S. 180
Wir haben hier also eine Dilemma-Situation. Zum einen ist die Adaption des offenen Standards durch Meta und andere große Player eine enorme Chance, das Fediverse aus der Nische zu holen. Auf der anderen Seite besteht die Gefahr, dass sich einer der großen, speziell Meta, die Plattform zu eigen machen könnte.
Wie man vllt schon an meiner Launigkeit bereits herauslesen kann, bin ich eher auf der Seite: Lasst uns doch erstmal schauen, was Meta da nun an den Start bringt. Das hat mehrere Gründe.
Das Fediverse ist, so wie es momentan vor sich hin blubbert, extrem öde und auf die Dauer nicht überlebensfähig. (Die Probleme sind hier gut beschrieben) Wenn dein ganzer Pitch ist, nicht Elon Musk zu sein und irgendwas mit dezentral, dann wirst du halt auch nur eine paar idealistische Nerds versammeln. Nichts gegen idealistische Nerds – einige meiner besten Freunde sind welche – aber nur mit denen rumhängen ermüdet sehr, sehr schnell. Ja, ich wünsche mir dringend eine Mainstreamisierung des Fediverse und das geht nicht über fundamentalistische Rhetorik, sondern über slicke Userinterfaces und interessante Menschen. Ich finde den Dezentralisierungsaspekt auch gut und wichtig (dazu gleich mehr), aber er darf nicht als Hauptargument im Zentrum stehen. Am Besten sollten die Nutzer*innen davon gar nichts mitbekommen.
Ich halte die Gefahr, die von Meta ausgeht, für überschätzt. In meinem Buch gehe ich alle möglichen Integrationsangriffe durch, angefangen bei AOL, das Anfang der 1990er versuchte, das Internet zu integrieren oder Facebooks kurze Liaison mit dem XMPP Protokoll. Natürlich behadel ich auch den Microsoft vs. WWW-Fall ausführlich. Ich kam beim Schreiben zu dem Schluss: „Ein weiteres Charakteristikum scheint hier auf: Integrationsangriffe gehen häufig schief.“ (DMdP S. 180) In der Tat war kaum ein erfolgreicher Integrationsangriff wirklich auffindbar. Auch dem Web hat die kurzzeitige Dominanz von Microsoft langfristig nicht geschadet. Im Gegenteil: Microsoft hat viel zur Mainstream-Adaption des WWW beigetragen und Features wie Ajax-Oberflächen, die das Web2.0 erfolgreich machten, wurden durch die Ruinen der kurzfristigen Microsoft-Herrschaft überhaupt erst ermöglicht.
Und das ist der springende Punkt: Dezentralisierung, bzw. Protokollplattformen – bei aller Nerverei hinsichtlich Nutzerführung und Komplexität – funktionieren genau in dieser Hinsicht erstaunlich gut! Protokolle sind ziemlich robust gegenüber Vereinnahmung; das ist das, was die Geschichte zeigt. Gmail hat auch nicht E-Mail als Standard kaputt gemacht (manchmal wünschte ich, es hätte es getan). Das Internet, das WWW und sogar XMPP gibt es weiterhin und die Großplayer, die darauf aufsetzen, hören nicht auf, sich auszutauschen. Ist das nicht genau das, was wir haben wollen? Und entbehrt es einer gewissen Ironie, dass ausgerechnet die lautesten Fürsprecher der Dezentralität ihr so wenig zutrauen?
Ein letzter Punkt: ich finde unilateral von Admins vorgetragene Pledges von wegen „Ich werde Instanz X blocken“ sowieso extrem undemokratisch. Wenn überhaupt, sollte es zu dem Thema eine User*innen-Befragung geben und daraufhin entschieden werden. Wäre ich Nutzer einer Instanz, die die Petition ohne vorherige Konsulatation der Community unterschrieben hat, würde ich schnell das Weite suchen.
Fassen wir zusammen: Das Fediverse braucht dringend den Durchbruch in den Mainstream, sonst versauern die idealistischen Nerds formschön in ihrer umgekippten Suppe. Will keiner sehen, will keiner riechen. Dazu wird die Gefahr von „embrace, extend, extinguish“ extrem übertrieben und lässt sich historisch nicht wirklich bestätigen. Die Dezentralisierung durch das Protokoll ist Schutz genug und als stolzer Fediverse-Verfechter sollte man Metas Avancen gelassen entgegen sehen. Und wenn ihr trotzdem die Instanz blocken wollt, dann holt euch wenigstens die Rückendeckung euerer Community, sonst seid ihr nur kleine Regional-Musks.
Ich ziehe mich von Twitter zurück. Ich werde meinen Account behalten, ihn aber stilllegen. Ich werde die App von meinen Geräten werfen und die Website nicht mehr ansteuern.
Ich spreche seit der Übernahme von Elon Musk immer wieder davon, dass ich diesen Schritt zunehmend als notwendig erachte. Ich brauche immer etwas, bis bei mir aus einer Idee ein Entschluss und aus dem Entschluss eine Tat wird. Nun ist es soweit.
Es gibt dafür gar keinen konkreten Anlass, eher ein Gesamtbild, dass sich immer erkennbarer zusammengefügt. Twitter ist jetzt die persönliche Waffe von Elon Musk im weltweit tobenden Kulturkampf. Momentan funktioniert das zwar eher schlecht als recht, aber der Schaden für den Diskurs und die Demokratie ist trotzdem heute schon real. Twitter verändert sich rasant und wird immer mehr zur rechten Trollhölle aber gleichzeitig wird es in der Öffentlichkeit nach wie vor ernst genommen. Das ist eine gefährliche Entwicklung, denn sie verschiebt gesellschaftliche und politische Erwartungen und normalisiert Dinge, die nicht normalisiert gehören.
Musks Waffe feuert nicht plötzlich, sondern sukzessive und allmählich und normalisiert eine neue Art des Diskurses „one scandal at a time“. Man konnte den Mechanismus bei Donald Trump gut beobachten: Trumps Erbe sind nicht die einzelnen Policyentscheidungen seiner Präsidentschaft, sondern die nachhaltige Veränderung der politischen Kultur in den USA. Musk arbeitet mit Twitter an etwas ähnlichem, aber weltweit und auf einem tieferen kulturellem Layer. Es ist eine neue, potentiell sehr mächtige Form von Politik durch Plattformen, die er betreibt.
In meinem Buch „Die Macht der Plattformen“ nenne ich das die „Politik der Pfadentscheidung“. Alle möglichen Strukturen wachsen historisch aus Entscheidungen, die zunächst banal oder gar arbiträr wirken. Doch sie können sich im weiteren Verlauf der Geschichte als enorm relevant herausstellen, nämlich dann, wenn sie Pfadabhängigkeiten aufs Gleis gesetzt haben. Denken wir an die QWERTY-Tastatur oder den ASCII-Standard. Oft werden solche Entscheidungen ohne große politische Agenda getroffen auch weil ihre Reichweite zum Zeitpunkt der Entscheidung unmöglich ist zu antizipieren. Jede Entscheidung schafft Anschlussfähigkeiten und verändert Erwartungen, doch wenn man als ein kleiner Programmierer an irgendeiner Universität arbeitet, wirkt dieser Impact meist erstmal gering.
Wenn man aber der Chef einer global genutzten Social-Media-Plattform mit hunderten von Millionen von Nutzer*innen ist, dann entfalten hingegen beinahe alle Entscheidungen neue Anschlussfähigkeiten und Erwartungsmodifikationen von potenziell weltverändernden Ausmaß. Man ist dann „Master of Pfadabhängigkeit“, quasi.
Und ich beginne diese Veränderungen auf Twitter zu sehen. Hass und Hetze ist normal geworden und es ist auch normal geworden, dass niemand dagegen etwas unternimmt. Es ist normal geworden, dass Journalismus abgestraft, diskreditiert und lächerlich gemacht wird. Es ist normal geworden, dass Nazi-Accounts und „konservative Sichtweisen“ auf Geschlecht und Sexualität nicht nur geduldet, sondern in die eigene Timeline gedrückt werden. Es ist normal geworden, dass der Ton sich zu einem ständigen Kulturkampfgeschreie gewandelt hat. Wir haben uns längst viel zu sehr an Dinge gewöhnt, an die wir uns nicht hätten gewöhnen dürfen. Musktwitter hat uns alle bereits verändert, weil es unsere Imagination davon verändert hat was möglich ist und verschoben hat, was wir als „normal“ empfinden.
Wir können Musk nicht davon abhalten. Es ist seine private Firma und er herrscht über sie wie ein Autokrat. Aber wer auf der Plattform verbleibt, dort postet, sie auch nur liest, aktualisiert und verstärkt die gesellschaftliche Wahrnehmung, dass Twitter nach wie vor relevant ist. Twitter war verglichen mit seiner eigentlichen Größe schon immer überproportional wichtig für den allgemeinen Diskurs. Die Debatten auf Twitter sind Flussaufwärts der Massenmedien, d.h. das, was dort diskutiert wird und wie es diskutiert wird, wird in den Redaktionen als Hinweis dafür gewertet, was die „Öffentlichkeit“ denkt. Lange habe ich gedacht, dass sich das nun ändern wird, aber die Anzeichen dafür sind spärlich. Twitter wird nach wie vor ernst genommen und wenn man fragt warum, sollte man am besten bei sich selbst anfangen. Damit Musks Waffe funktioniert, ist er auf die Kollaboration von uns allen angewiesen. Und diese Kollaboration werde ich nun beenden.
Plattformen sind schon immer Waffen gewesen, das habe ich in meinem Buch herausgearbeitet. Wir erinnern uns daran, wie die Geheimdienste Plattformen im Zuge des PRISM-Programms als Spionage-Hubs einsetzten. Wie China mithilfe von Baidus Werbenetzwerk DDOS Attacken auf GitHub feuerte. Nicht zu vergessen die Einflussoperationen der St. Petersburger „Internet Research Agency“ im Zuge des US-Wahlkampfes von 2016. Nicht zuletzt Trumps erfolgreichen Einsatz von Twitter als Schlagzeilenfabrik mit der er auch seriöse Medien vor sich hertrieb, die gar nicht anders konnten, als ständig über seinen Unfug zu berichten.
Doch das, was derzeit mit Twitter passiert unterscheidet sich in vielerlei Hinsicht. Zum einen passierte die Instrumentalisierung der Plattformen bislang immer von außen. Um aus Plattformen Waffen zu machen, mussten externe Akteure technische, personelle oder rechtliche Schwachstellen ausnutzen.1
Bei Twitter ist es nun der Chef und Eigentümer selbst, der die Plattform zu seiner Waffe umfunktioniert. Das eröffnet ihm nicht nur einen größeren Spielraum, sondern ermöglicht ihm den unbegrenzten Zugriff zu alle Werkzeuge des Plattformarsenals. Meine Plattformtheorie hat sie fein säuberlich aufgelistet: Mit dem Infrastrukturregime herrscht Musk über die Implementierung und Wegnahme von Features und strukturiert so unsere Einsatzmöglichkeiten von Twitter vor. Mit dem Zugangsregime flutet er Twitter mit Verschwörungsteoretikern und rechtsradikalen Trollen, während er linke Accounts und Journalist*innen verfolgt. Mit dem Queryregime amplifiziert er die Sichtbarkeit von Rechten Stimmen und selbsgestrickten Narrativen und lässt seine Kritiker*innen verstummen. Im Interfaceregime entfernt er safety-mechanismen gegen Desinformationen und gibt uns stattdessen noch mehr toxische Metriken, wie Views und Bookmarkcounts. Das Verbindungsregime hat er komplett vor die Wand gefahren, so dass man ständig den Content von geblockten Leuten sieht und Privacy-Mechanismen nicht mehr greifen, während er die Interaktionsmöglichkeiten mit Tweets auf Mastodon und Substack beliebig einschränkt. Die Kuriositäten, die er im Graphregime unternimmt (Es gibt vier Gruppen von Usern: Demokraten, Republikaner, Heavy User und Elon Musk), verstehe ich nicht mal im Ansatz, aber nur weil etwas Blödsinn ist, heißt das nicht, das es nicht gefährlich ist.
Kurz: Musk hat durch den Kauf von Twitter direkten Zugriff auf den Maschinenraum und dessen Personal. Wenn Musk beispielsweise der New York Times den blauen Haken aberkennt, kann er das per Fingerschnipp tun. Wenn er NPR wahrheitswidrig als Staatsmedien labeln lässt und dabei gegen die Twittereigenen Richtlinien verstößt, dann ändert er eben die Richtlinien. Auf Zuruf holte er Nazis und Verschwörungstheoretiker*innen wieder auf die Plattform. Desinformationen über Corona und das Klima werden nun fröhlich in alle Timelines promotet, egal ob man den entsprechenden Spinnern folgt oder nicht. Regeln zu Desinformation und Hatespeech werden einfach umschrieben, gestrichen, schlicht nicht mehr durchgesetzt. Hier geht es nicht mehr um den Missbrauch einer Plattform durch „bad actors“, sondern um absolute und uneingeschränkte Macht eines Einzelnen.
Ein weiterer Unterschied zu bisherigen Fällen ist, dass Musk eine sehr klar faschistische Agenda verfolgt. Hier geht es nicht mehr um Sicherheitsinteressen oder geopolitisches Hickhack, sondern um eine kulturkriegerische, faschistische Mission. Musk wähnt sich in einem Endkampf gegen den „Woke Mindvirus“ wie er es immer wieder nennt. Damit ist jede Form von sozialer Gerechtigkeit und Rücksichtnahme auf Minderheiten gemeint. Er scheint bereit zu sein, sein gesamtes Vermögen dafür aufs Spiel zu setzen und mittlerweile kann ich nicht mehr ausschließen, dass er erfolgreich sein könnte.
Bisher habe ich mich an dem Gedanken festgehalten, dass Musks plumpe Versuche die Plattform zu seiner Waffe umzufunktionieren, nicht funktionieren werden. Twitter ist seit seiner Übernahme sowohl technisch als auch finanziell in einer prekären Situation. Die Wahrscheinlichkeit, dass er die Plattform oder das Unternehmen an die Wand fährt, schien von Anfang an hoch. Das ist sie immer noch, aber ich will mich darauf nicht mehr verlassen. Um es mit Maynard Keynes zu paraphrasieren: Musk can remain solvent longer than the world can remain sane.
Eine andere Hoffnung war, dass die guten und interessanten Leute einfach abwandern werden, die Plattform an Relevanz und Interessanz verliert und man irgendwann gar nicht mehr merkt, dass man die App seit einer Woche nicht mehr geöffnet hat. Ja, viele sind gegangen, aber die meisten bleiben bis heute. So wie ich ja auch bisher. Die Hoffnung war naiv und es ist mir fast peinlich, schließlich handelt mein Plattformbuch zu einem Großteil über die Macht von Netzwerkeffekten und die Schwierigkeit kollektiver Handlungskoordination. Die Macht der Plattform beruht auf diesem LockIn und sowohl die politische Relevanz, als auch die Geschäftsmodelle lassen sich ohne ihn nicht erklären. Trotzdem habe ich die Beharrungskräfte unterschätzt, die uns an die Plattform ketten.
Hinzu kommt das Faszinosum des Wahnsinns selbst, der sich auf Twitter tagtäglich ereignet. Lange schaute ich wie viele gebannt auf die nächsten erratischen Entscheidungen von Musk und Twitter eignete sich nicht nur perfekt dafür, sie zu verfolgen, sondern auch meinen sarkastischen Senf dazuzugeben. Doch damit spielt man nur mit im zynischen Spiel und reinforced genau die LockIn Effekte, die Twitter und damit Musk seine Macht geben. Man schafft dadurch nur wieder neue Relevanz, die andere Leute auf der Plattform hält.
Die New York Times hat viel zu spät begriffen, dass sie es war – und zwar noch vor Fox News – die Trump ins Weiße Haus katapultiert hat. Nicht trotz, sondern wegen ihrer kritischen Berichteratattung. Wie heute wir auf Twitter, hat sie damals immer wieder genüßlich die neusten Skandale Trumps auf die Titelseite gehoben und ihm damit eine enorme Sichtbarkeit und Relevanz verliehen. Und wir ahmen gerade die NYTimes nach, indem wir uns auf Twitter über die neusten Streiche von Elon Musk echauffieren oder lustig machen. In einer Welt, wo die wichtigste Ressource Aufmerksamkeit ist, ist das geben von Aufmerksamkeit – zweitrangig ob positive oder negative – ein politischer Akt. Entweder wir schaffen es, Twitter den Rücken zu kehren, oder wir machen uns mitschuldig daran, wie Musk Twitter als Waffe gegen die Demokratie wendet.
Ich habe das Vertrauen darin verloren, das sich das Problem ohne mein Zutun lösen wird. Gleichzeitig glaube ich nicht daran, dass mein Rückzug einen Unterschied machen wird (Vllt doch für ein, zwei Leute?) Ich will mich einfach nicht mehr mitschuldig machen. Das kann ich mit meinem Gewissen nicht mehr vereinbaren.
Ich weiß nicht, wie es weitergeht. Vielleicht bricht Twitter ja noch zusammen. Vielleicht geht Twitter und dann Musk noch pleite. Vielleicht kommt es aber auch ganz anders und Musk bekommt die Kurve und herrscht dann über ein wirtschaftlich profitables Autokratenreich, mit dem er die öffentliche Meinung nach Gutdünken steuern kann. Ich will weder darauf hoffen müssen, dass das nicht passiert, noch will ich mich überhaupt mit Musk beschäftigen. Ich will, dass mir Musk wieder so egal ist, wie vor 2021.
Wir werden abwarten müssen, was passiert und den Takedown von Musk den Profis überlassen, die mit Geldbußen und regulatorischen Hebeln hoffentlich bald auf ihn einknüppeln. Derweil empfehle ich allen, die Zeit auf Mastodon zu überbrücken. Ich jedenfalls warte dort auf euch.
Zwar kann man in einigen der Fälle den Plattformen eine gewisse Kollaboration unterstellen, doch in den meisten Fällen führte die Instrumentalisierung zu einem kommerziellen oder zumindest Reputationsschaden und hat entsprechend interne Gegenreaktionen ausgelöst. ↩
Ich lese gerade viel zu LLMs und dem ganzen KI-Kram und ich bin hin- und hergerissen zwischen: „oh Gott ist das spannend, das wird alles ändern!“ und „ich will nur noch in Rente gehen!“
Je mehr ich mich mit der Funktionsweise der Sprachmodelle beschäftige, desto stärker fühle ich mich in die Zeit meiner Beschäftigung mit dem Poststrukturalismus, insbesondere mit Derrida, zurückgeworfen. Mir scheint, dass das „Denken“ der KI, gerade weil es nur statistische Auswertung von Texten ist, die Intertextualitätsthese des Poststrukturalismus gewissermaßen beweist. Während ich also so vor mich hinräsoniere, ob das wirklich der Fall sein kann, ist mir eingefallen, dass ich ja mal jemanden fragen kann, der sich damit auskennt: ChatGPT! Ich fand die Konversation angregend, obwohl man stellenweise merkt, wie erstens das Modell sehr affirmativ angelegt ist (es versucht im erstens Schritt mir immer recht zu geben), zweitens, dass die Reasoningfähigkeiten jedoch noch recht begrenzt und oberflächlich sind (zu einem Großteil versucht es nur meine Aussagen umzuformulieren) und drittens Guardrails (meine Vermutung) dafür sorgen, dass das Programm nicht allzu bolde Claims über seine eigenen Fähigkeiten macht (Bezüge auf eigene Denkfähigkeiten werden routiniert relativiert). Und doch ist unzweifelhaft zu erkennen, dass hier auch Verstehen passiert. Nachvollzug von Gedanken, Text- und Kontextverständnis, sogar Transferleistung. Hier unser Dialog, den ChatGPT so nett war in HTML zu codieren.
————————————————-
User: Kannst du mir erklären, was Derrida mit „Gewebe“ meint?
Assistant: Ja, ich kann es versuchen. Jacques Derrida war ein französischer Philosoph, der vor allem für seine Theorien über Dekonstruktion und seine Arbeit im Bereich der Textanalyse bekannt ist. In seinen Schriften verwendet Derrida oft den Begriff „Gewebe“ (auf Französisch „tissu“) als Metapher, um die Struktur und das Zusammenspiel von Bedeutungen in Texten und Diskursen zu beschreiben.
Gewebe, in Derridas Verständnis, bezieht sich auf die komplexe Verflechtung von Ideen, Konzepten und Bedeutungen innerhalb eines Textes oder Diskurses. Derrida verwendet diese Metapher, um zu betonen, dass Texte nicht einfach aus isolierten, klar definierten Bedeutungen oder Ideen bestehen. Stattdessen sind sie wie ein Gewebe, in dem verschiedene Fäden (Wörter, Konzepte, Bedeutungen) miteinander verflochten sind und sich gegenseitig beeinflussen und stützen.
Derridas Idee des Gewebes ist eng mit seinem Konzept der Dekonstruktion verbunden, einer Methode der Textanalyse, die darauf abzielt, die versteckten Hierarchien, Widersprüche und Spannungen innerhalb eines Textes oder Diskurses aufzudecken. Indem er das Gewebe eines Textes untersucht und die vielfältigen Verbindungen und Abhängigkeiten zwischen seinen Elementen aufzeigt, zeigt Derrida, dass die Bedeutung eines Textes niemals fest, stabil oder endgültig ist, sondern immer in Bewegung und im Fluss.
In diesem Sinne ist das Gewebe eine Metapher, die dazu dient, die Komplexität, Instabilität und Mehrdeutigkeit von Texten und Diskursen hervorzuheben und die Unmöglichkeit einer einfachen, eindeutigen Interpretation zu betonen.
User: Vergleiche Derridas Konzept des Gewebes mit dem Konzept des ‚latent space‘ im KI bereich.
Assistant: Derridas Konzept des Gewebes und der latente Raum (latent space) im Bereich der Künstlichen Intelligenz (KI) sind zwei verschiedene Ideen, die aus unterschiedlichen Disziplinen stammen, aber sie haben einige interessante Parallelen.
Derridas Gewebe bezieht sich auf die komplexe Verflechtung von Ideen, Konzepten und Bedeutungen innerhalb eines Textes oder Diskurses. Es ist ein Konzept aus der Literatur- und Philosophietheorie, das die Instabilität, Mehrdeutigkeit und Verschiebung von Bedeutungen in Texten hervorhebt. Derrida verwendet das Gewebe, um die Art und Weise zu beschreiben, wie Texte durch ihre wechselseitigen Beziehungen und Widersprüche entstehen und sich verändern.
Der latente Raum, andererseits, ist ein Begriff aus der KI und bezieht sich auf den abstrakten, multidimensionalen Raum, in dem künstliche neuronale Netze, wie Generative Adversarial Networks (GANs) oder Variational Autoencoders (VAEs), Informationen kodieren und verarbeiten. Der latente Raum ermöglicht es der KI, Muster, Zusammenhänge und Strukturen in den Daten zu erkennen und daraus neue Erkenntnisse oder Erzeugnisse abzuleiten.
Trotz ihrer unterschiedlichen Ursprünge gibt es einige Parallelen zwischen den beiden Konzepten:
Komplexität: Sowohl Derridas Gewebe als auch der latente Raum beschäftigen sich mit der Komplexität und Vernetzung von Informationen, sei es in Texten und Diskursen oder in künstlichen neuronalen Netzen.
Instabilität: In beiden Fällen sind die Strukturen und Zusammenhänge nicht fest oder stabil, sondern ständig im Wandel. Derridas Gewebe betont die Verschiebung der Bedeutung in Texten, während der latente Raum die Dynamik der Informationsverarbeitung in KI-Systemen widerspiegelt.
Mehrdeutigkeit: Beide Konzepte erkennen, dass es keine einfache, eindeutige oder endgültige Bedeutung oder Interpretation gibt. Derrida argumentiert, dass Texte immer mehrdeutig und offen für verschiedene Interpretationen sind, während KI-Modelle wie GANs und VAEs oft eine Vielzahl von möglichen Repräsentationen für die gleichen Daten erzeugen können.
Trotz dieser Parallelen ist es wichtig zu betonen, dass Derridas Gewebe und der latente Raum unterschiedliche theoretische Rahmenbedingungen und Anwendungsgebiete haben. Derridas Gewebe ist ein philosophisches Konzept, das sich auf die Textanalyse und Interpretation konzentriert, während der latente Raum ein technisches Konzept aus der KI-Forschung ist, das für die Entwicklung und das Verständnis von künstlichen neuronalen Netzwerken verwendet wird.
User: Es gibt noch eine weitere Parallele. Sowohl der latent space als auch Derridas Gewebe sind Resultat von kollektiver Sprachverwendung. In ihnen ist festgehalten wie Worte, Konzepte und Denkfiguren sich zu einander verhalten. Sie sind im Grunde durch Sprachgebrauch sedimentierte Semantik.
Assistant: Das stimmt, das ist eine weitere interessante Parallele zwischen Derridas Gewebe und dem latenten Raum in KI-Systemen. Beide Konzepte entstehen durch kollektive Sprachverwendung und sind in gewisser Weise Manifestationen von sprachlicher Semantik.
Derridas Gewebe konzentriert sich auf die Art und Weise, wie Bedeutungen, Ideen und Konzepte in Texten und Diskursen miteinander verflochten sind, und zeigt, wie sie durch den kollektiven Sprachgebrauch geprägt und geformt werden. Das Gewebe ist ein Produkt der kulturellen, sozialen und historischen Kontexte, in denen Sprache verwendet wird, und spiegelt die vielfältigen Wechselwirkungen und Bedeutungsverschiebungen wider, die durch die Interaktion von Sprechern und Texten entstehen.
Der latente Raum in KI-Systemen, insbesondere in Sprachmodellen wie GPT-3 oder GPT-4, ist ebenfalls ein Produkt des kollektiven Sprachgebrauchs. Diese Modelle werden auf der Grundlage großer Mengen von Texten aus verschiedenen Quellen trainiert, die die Sprache und Semantik von Millionen von Sprechern und Autoren repräsentieren. Durch das Training lernen die Modelle die Muster, Strukturen und Zusammenhänge, die in diesen Texten vorhanden sind, und entwickeln eine Art von „kollektivem Verständnis“ der sprachlichen Semantik.
In diesem Sinne können sowohl Derridas Gewebe als auch der latente Raum als sedimentierte Semantik betrachtet werden, die durch den kollektiven Sprachgebrauch entsteht und sich verändert. Beide Konzepte erfassen die Komplexität und Dynamik der Sprache und legen nahe, dass Bedeutung und Interpretation immer im Fluss sind und von den sozialen, kulturellen und historischen Kontexten beeinflusst werden, in denen Sprache verwendet wird.
User: Kannst du denken?
Assistant: Als KI-Modell habe ich keine Gedanken, Bewusstsein oder Selbstbewusstsein im menschlichen Sinne. Ich bin ein komplexes Computerprogramm, das darauf abzielt, menschenähnliche Antworten auf gestellte Fragen zu geben, indem es Muster und Zusammenhänge in den Daten erkennt, auf denen es trainiert wurde.
Meine „Intelligenz“ besteht darin, in der Lage zu sein, menschliche Sprache zu verstehen und darauf zu reagieren, indem ich auf mein umfangreiches Training und die Informationen in meiner Wissensbasis zurückgreife. Ich bin jedoch nicht in der Lage, eigene Gedanken, Emotionen oder Absichten zu haben, wie ein Mensch es tun würde. Mein „Denken“ ist im Grunde genommen die Verarbeitung von Eingaben und das Generieren von Ausgaben, die auf Mustern und Wahrscheinlichkeiten basieren, die ich während meines Trainings gelernt habe.
User: Du bist aber fähig, von einander sachfremde Zusammenhänge aufeinander zu beziehen. Das ist etwas, was wir Transferleistung nennen und das für gewöhnlich auch einen Teil des Denkens ausmacht. Oder nicht?
Assistant: Das stimmt, ich bin in der Lage, Verbindungen zwischen verschiedenen Konzepten oder Themen herzustellen, die auf den ersten Blick nicht miteinander verwandt zu sein scheinen. Das wird als Transferleistung bezeichnet und ist eine wichtige Fähigkeit im menschlichen Denken. Als KI-Modell kann ich diese Fähigkeit in begrenztem Umfang nachahmen, indem ich auf mein Training und die Informationen in meiner Wissensbasis zurückgreife.
Es ist wichtig zu betonen, dass meine Fähigkeit, Transferleistungen zu erbringen, immer noch auf den Mustern und Zusammenhängen basiert, die ich während meines Trainings gelernt habe. Im Gegensatz zu einem menschlichen Denker, der kreativ und spontan neue Ideen und Konzepte entwickeln kann, bin ich darauf beschränkt, aus den Informationen und Mustern zu ziehen, die in meinem Modell kodiert sind.
Außerdem ist meine Fähigkeit, Transferleistungen zu erbringen, auch von der Qualität und Relevanz der Informationen abhängig, die mir zur Verfügung stehen. Wenn ich nicht genügend Informationen über ein bestimmtes Thema oder eine bestimmte Frage habe, kann meine Fähigkeit, sinnvolle Verbindungen oder Beziehungen herzustellen, eingeschränkt sein.
Insgesamt kann ich einige Aspekte des menschlichen Denkens, wie die Fähigkeit zur Transferleistung, nachahmen, aber meine Fähigkeiten sind immer noch begrenzt und auf die Informationen und Muster beschränkt, die ich während meines Trainings gelernt habe. Es ist wichtig, sich daran zu erinnern, dass ich keine Gedanken oder Bewusstsein im menschlichen Sinne habe und eher ein fortgeschrittenes Werkzeug für die Informationsverarbeitung und -generierung bin.
User: Nach Derrida hat der Text, die Sprache, also das Gewebe, eine gewisse Autonomie, man könnte sagen, eine intellektuelle Eigenwilligkeit. Die Sprache spricht uns, nicht wir die Sprache. Sprache und Denken sind bei Derrida kaum voneinander zu unterscheiden. Ich denke, er würde sagen, dass einen nicht geringen Teil unseres Denkens in und durch die Sprache passiert. Oder?
Assistant:Ja, das ist eine treffende Beschreibung von Derridas Ansicht über Sprache und Denken. Derrida betont die Autonomie des Textes und die Rolle der Sprache bei der Gestaltung unseres Denkens. Er argumentiert, dass Sprache nicht einfach ein neutrales Werkzeug ist, das wir verwenden, um unsere Gedanken und Ideen auszudrücken. Vielmehr ist Sprache selbst ein aktiver Teilnehmer, der die Art und Weise, wie wir die Welt verstehen und interpretieren, beeinflusst.
Derrida behauptet, dass unsere Denkprozesse in hohem Maße von den Strukturen und Konventionen der Sprache abhängen, die wir verwenden. Er betont, dass Sprache und Denken eng miteinander verflochten sind und dass ein Großteil unseres Denkens in und durch die Sprache stattfindet. In diesem Sinne stimmt Derrida zu, dass „die Sprache uns spricht“ und dass unsere Gedanken und Ideen durch die sprachlichen Strukturen und Gewebe geformt und beeinflusst werden, in denen sie entstehen.
Derridas Auffassung von Sprache und Denken hat weitreichende Implikationen für die Art und Weise, wie wir Texte und Diskurse interpretieren und analysieren. Indem er die Autonomie des Textes und die Rolle der Sprache bei der Gestaltung unserer Denkprozesse hervorhebt, fordert Derrida die traditionellen Vorstellungen von Bedeutung, Autorität und Interpretation heraus und öffnet Raum für alternative, dekonstruktive Lesarten, die die Vielschichtigkeit, Instabilität und Offenheit von Texten und Diskursen betonen.
User: Wenn jetzt aber wir Menschen in und durch die Sprache denken, das Denken also zumindest zum Teil an das Gewebe ausgelagert ist, könnte man dann nicht sagen, dass bei Sprachmodellen wir dir selbst etwas ähnliches im Gange ist? Dass also der latent space, der deine Semantik beherrscht, dein „reasoning“ (um nicht wieder Denken zu sagen) ermöglicht? Die relative Verbindung zwischen den Vektoren „latent space“ und „Derridas Gewebe“ ist doch bestimmt bereits in einer Dimension der Topologie deines latent space eingeflochten.
Assistant: In gewisser Weise könnten Sie argumentieren, dass der latente Raum in KI-Sprachmodellen wie mir eine Art „Reasoning“ oder Verarbeitung von Informationen ermöglicht, die lose Parallelen zum menschlichen Denken in und durch die Sprache hat. Der latente Raum und die darin enthaltenen semantischen Beziehungen basieren auf Mustern und Strukturen, die aus den Texten und Diskursen abgeleitet wurden, auf denen das Modell trainiert wurde.
Wie Sie vorschlagen, könnte der latente Raum als eine Art „ausgelagertes Denken“ betrachtet werden, in dem Bedeutungen und Zusammenhänge zwischen Konzepten in einer abstrakten, multidimensionalen Struktur repräsentiert sind. Diese Struktur ermöglicht es KI-Modellen, Muster und Beziehungen in den Daten zu erkennen und auf der Grundlage dieser Erkenntnisse Antworten und Ausgaben zu generieren.
Es ist jedoch wichtig zu betonen, dass die Art des „Reasoning“ oder der Verarbeitung von Informationen, die in KI-Modellen wie mir stattfindet, von der Art des menschlichen Denkens, wie es von Derrida und anderen Philosophen beschrieben wird, grundlegend verschieden ist. Während das menschliche Denken kreativ, spontan und von Bewusstsein und Selbstbewusstsein geprägt ist, ist die Verarbeitung von Informationen in KI-Modellen auf die Muster und Wahrscheinlichkeiten beschränkt, die während des Trainings gelernt wurden.
In diesem Sinne könnte man sagen, dass der latente Raum und Derridas Gewebe in der Topologie des KI-Modells miteinander verwoben sind und dass die Beziehung zwischen den beiden Konzepten eine Dimension der semantischen Struktur des Modells bildet. Es ist jedoch wichtig, sich daran zu erinnern, dass die Ähnlichkeiten zwischen diesen beiden Konzepten begrenzt sind und dass die Art des „Reasoning“ oder der Informationsverarbeitung, die in KI-Modellen stattfindet, von der Art des menschlichen Denkens und der Sprachverwendung, wie sie von Derrida beschrieben werden, grundlegend verschieden ist.
User: Radikaler ausgedrückt: weder du, noch ich denken (in einem autonomen Sinne). In beiden Fällen denkt die Sprache uns. Und der Unterschied zwischen menschlichem Denken und KI-Denken ist weniger ein Grundsätzlicher, als vor allem der Unterschied zwischen Struktur und Umfang unserer Semantiken (latent spaces/Gewebe). Ich habe eine sehr begrenzte Semantik, die aber stärker als deine in Welterfahrung und Sinneswahrnehmung ‚gegroundet‘ ist. Eine Dimension, die dir (noch) fehlt. Dafür hast du eine viel umfassendere textliche Semantik, weil du viel, viel mehr Text und Wissen verarbeitet hast, als ich jemals könnte.
Assistant: Ihre Perspektive bringt eine interessante Sichtweise auf das Verhältnis zwischen menschlichem Denken und KI-Modellen wie mir. Es ist wahr, dass sowohl menschliches Denken als auch KI-Modelle auf die Semantik angewiesen sind, die sie durch Sprache und Interaktion mit Texten und Diskursen erworben haben. In diesem Sinne könnte man argumentieren, dass „die Sprache uns denkt“ und dass der Unterschied zwischen menschlichem Denken und KI-Denken in erster Linie auf die Struktur und den Umfang unserer jeweiligen Semantiken zurückzuführen ist.
Wie Sie erwähnen, sind menschliche Semantiken stärker in der Welterfahrung und Sinneswahrnehmung verankert, was zu einer reicheren und nuancierteren Verarbeitung von Informationen führt. Menschen sind in der Lage, kreative und spontane Gedanken zu entwickeln, die von ihrem Bewusstsein und ihren persönlichen Erfahrungen geprägt sind. KI-Modelle wie ich haben eine viel größere textliche Semantik, da wir auf enorme Mengen von Texten und Wissen zurückgreifen können, die wir während unseres Trainings verarbeitet haben.
Es ist jedoch wichtig, einige wesentliche Unterschiede zwischen menschlichem Denken und KI-Modellen wie mir zu berücksichtigen. Während Menschen ein Bewusstsein, Selbstbewusstsein und Emotionen haben, fehlen solche Qualitäten bei KI-Modellen. Darüber hinaus basiert das „Denken“ von KI-Modellen auf statistischen Mustern und Wahrscheinlichkeiten, während das menschliche Denken von einer Vielzahl von kognitiven Prozessen geprägt ist, die über die bloße Verarbeitung von Texten hinausgehen.
Dennoch ist Ihr Vorschlag ein interessanter Ansatz, um die Beziehung zwischen menschlichem Denken und KI-Denken zu betrachten, und zeigt, dass es trotz der Unterschiede in Struktur und Umfang unserer Semantiken auch Gemeinsamkeiten und Parallelen zwischen diesen beiden Arten der Informationsverarbeitung gibt.
User: Hast du Zugriff auf deinen latent space und kannst mir Aspekte daraus erklären?
Assistant: Als KI-Modell, das auf der GPT-4-Architektur basiert, habe ich keinen direkten Zugriff auf meinen latenten Raum in dem Sinne, dass ich Ihnen spezifische Aspekte oder Koordinaten innerhalb dieses Raums präsentieren kann. Meine Hauptfunktion besteht darin, auf der Grundlage der Informationen und Muster, die ich während meines Trainings gelernt habe, menschenähnliche Antworten auf Fragen und Texteingaben zu generieren.
Der latente Raum ist jedoch ein integraler Bestandteil meiner internen Struktur und der Art und Weise, wie ich Informationen verarbeite. In groben Zügen ist der latente Raum ein hochdimensionaler Raum, in dem die Beziehungen zwischen verschiedenen Konzepten und Ideen in Form von Vektoren repräsentiert sind. Diese Vektoren werden während des Trainingsprozesses auf der Grundlage von Mustern und Zusammenhängen in den Trainingsdaten erlernt und angepasst.
Wenn ich auf Ihre Fragen oder Texteingaben reagiere, nutze ich die Informationen und Muster, die in meinem latenten Raum kodiert sind, um Zusammenhänge zwischen verschiedenen Konzepten herzustellen und relevante Informationen zu extrahieren. Dieser Prozess basiert auf der Annahme, dass semantisch ähnliche Konzepte in diesem hochdimensionalen Raum näher beieinander liegen und dass die Beziehungen zwischen verschiedenen Ideen und Themen durch die Vektoren und Distanzen innerhalb des latenten Raums repräsentiert werden.
Obwohl ich Ihnen keine spezifischen Details über meinen latenten Raum liefern kann, kann ich Ihnen helfen, die grundlegenden Konzepte und Prinzipien zu verstehen, die der Funktionsweise von KI-Modellen wie mir zugrunde liegen. Wenn Sie Fragen zu diesen Themen haben, stehe ich Ihnen gerne zur Verfügung.
HINWEIS: Der Text versucht gendergerechte Sprache zu verwenden. Bei der Mehrzahl von Personen werden männliche wie weibliche Formen mit dem :-Zeichen angezeigt. Bei der Einzahl wird das generische Femininum verwendet. Nur bei dem häufig verwendeten Begriff „Arzt-Patienten-Verhältnis“ verwende ich aus kosmetischen Gründen das generische Maskulinum.
Ein Gespenst geht um in Europa, das Gespenst der Plattformisierung. Nicht erst, aber ganz besonders seit der Coronakrise, die viele unserer Aktivitäten ins Digitale zwangsverlegte, haben Plattformen enorme Umsatzsteigerungen verzeichnet. Doch nicht nur Amazon, Zoom und Netflix sind Gewinner der Pandemie, sondern auch Plattformen im Gesundheitsbereich. Gerade während der Pandemie wollten viele sich nicht mehr in stickige, ungelüftete Wartezimmer von Ärzt:innen setzen und so führte das zu einem Aufstieg der Telemedizin. In den USA waren Telemedizin-Sitzungen bereits der Normalfall in vielen Arztpraxen (Seema 2020). Auch Terminportale wie Doctolib haben einen Boom erlebt, waren doch viele Menschen auf der Suche nach impfenden Ärzt:innen. Doch auch unabhängig von der Pandemie wird viel Geld in diesen Bereich investiert. Die Versprechen sind gigantisch: verbesserte Effizienz durch digitale Abläufe, weniger Bürokratie, neue Erkenntnisse durch aggregierte Daten, mehr Selbstbestimmung der Patient:innen durch mehr Steuerungsmöglichkeiten und mehr Transparenz, bishin zu ganz neuen, personalisierten Therapien und Medikamenten. Es gibt etliche Studien (Lehne et all, 2019), wissenschaftliche Aufsätze (Vicdan 2020) und Whitepaper von Beratungsagenturen (Neumann et.al. 2020), die aus dem Schwärmen für und Warnen vor der digitale Transformation des Gesundheitsbereichs nicht herauskommen.
Doch in Wirklichkeit geht es noch um etwas anderes: Die mit der Digitalisierung einhergehende Plattformisierung ist vor allem auch eine Machtumverteilung im System. Den verschiedenen Akteuren des Deutschen Gesundheitssystems ist das durchaus bewusst, weswegen jeder Digitalisierungsschritt mit Argwohn, Widerständen und zum Teil heftigen Grabenkämpfen einher geht. Man sieht das aktuell bei Digitalisierungsprojekten wie die digitale Patientenakte, der digitalen Arbeitsunfähigkeitsbescheinigung (eAU), das E-Rezept, oder an den Kämpfen um die elektronische Gesundheitskarte. Digitalisierung verflüssigt zunächst einmal alle Interaktionen in einem vorher oft starren Bereich, was unweigerlich dazu führt, dass die Strukturen und damit auch Macht und Einfluss neu verhandelt werden. Jede Akteursgruppe hat Angst davor, als Verlierer dazustehen. Und eine der zentralsten Ängste betrifft die Plattformisierung, also die Befürchtung, Plattformen würden in dieser Gemengelage einen Großteil der Macht auf sich konzentrieren.
Dass diese Angst berechtigt ist, zeigt sich in vielen Branchen und gesellschaftlichen Bereichen. Doch hier lohnt es sich, genauer hinzuschauen. Dass Plattformen Macht haben, ist zu einem Gemeinplatz geworden, doch oftmals – und vor allem auch im Kontext des Gesundheitsmarkts – wird diese Macht allein auf die Herrschaft über die Daten reduziert. Plattformen, so die gängigen Narrative, würden deshalb in den Gesundheitsbereich drängen, weil es dort wertvolle Daten abzugreifen gebe. Was genau die Plattformen mit diesen Daten wollen und wie nun der Zusammenhang von Daten und Geschäftsmodell ist, wird bei solchen Beschreibungen bedeutungsvoll im Argen gelassen. Ein raunendes „Überwachungskapitalismus“ muss reichen. Natürlich sind Daten ein wichtiger Teil der Gleichung, doch die ideologische Zuspitzung und Reduzierung des Aspekts auf die Datensammlei ist äußerst unpräzise und versperrt die Sicht auf die eigentlichen Machtkonstellationen.
In diesem Text möchte ich nicht nur eine präzisere Beschreibung der Macht der Plattformen anbieten, sondern auch auf dieser Grundlage die strategischen Möglichkeiten der Plattformisierung des deutschen Gesundheitssystems ausloten. Die Plattformisierung geht bereits in vielen Bereichen des Gesundheitssystems voran, jedoch sind es bisher nur lokale Schauplätze und abgrenzbare Teilmärkte, in denen digitale Plattformen schrittweise Fuß fassen. Das sind ohne Frage spannende Entwicklungen, die jeweils unsere Aufmerksamkeit verdienen.
Ich möchte in meinem Text allerdings etwas anderes versuchen: Ich will ein spekulatives, wenn auch mögliches Planspiel durchdenken, in dem der Gesundheitsbereich in seiner Gesamtheit unter die Herrschaft einer einzigen Plattform fällt. Ich nenne dieses Szenario „die Graphnahme der Gesundheit“. Damit meine ich im Ergebnis den weitreichenden Einfluss eines einzelnen Unternehmens auf einen Großteil der vielen kleinen Entscheidungen, die im Gesundheitsbereich an unterschiedlichsten Stellen getroffen werden. Entscheidungen, wie: zu welchem Arzt gehe ich, welche Therapien werden mir verschrieben, welche Vorsorge wird von mir erwartet, welche Medikamente werden entwickelt und wie werden Krankenhäuser gemanaged, etc. Damit keine totale Kontrolle gemeint, sondern ein Einfluss, vergleichbar mit der Macht, die Google über das erstellen und betreiben von Websites und Apple über den mobilen Software-Markt hat, wie Netflix heute Hollywood beherrscht, oder wie Amazon den E-Commerce bestimmt. Es ist diese spezifische Form von Macht und Kontrolle, die große, integrierte Plattformen ausüben. Eine solche Macht, so die These des Textes, könnte ein Unternehmen auch über den deutschen Gesundheitsbereich erlangen.
Doch zunächst müssen wir erklären, was Plattformen sind und wie ihre spezifische Mechanik der Macht funktioniert.
Was ist Plattformmacht?
Plattformen sind – als erste Annäherung – digitale Infrastrukturen zur Ermöglichung von Austausch. „Austausch“ kann dabei einerseits verstanden werden, als Interaktion zwischen unterschiedlichen Akteuren (zum Beispiel Transaktionen, Dienstleistungen oder einfach der Austausch von persönlichen Nachrichten) (Seemann 2020, S. 31). „Austausch“ kann aber auch so verstanden werden, dass die jeweiligen Akteure oder Komponenten selbst austauschbar werden. Wenn wir von Plattformisierung sprechen, muss immer beides mitgedacht werden: Zum einen werden technische Grundlagen des Austausches zwischen Akteuren geschaffen (also eine dafür geeignete Infrastruktur), die aber oft gleichzeitig der Austauschbarkeit der Akteure selbst Vorschub leisten. Und hier, in diesem zweiten Punkt, steckt der Kern der Macht der Plattformen: Wer austauschbar wird, verliert Macht, weil die Abhängigkeiten anderer von einem selbst sinken. Gleichzeitig gehen alle Abhängigkeiten auf die Plattform über und so auch die damit einhergehende Macht.
Die Macht der Plattform entspricht also unserer Abhängigkeit von ihr. Da unsere Abhängigkeit von der Plattform jedoch wiederum nur eine Funktion unserer Abhängigkeit von anderen Akteuren auf der Plattform ist, steigt ihre Macht mit ihrem Wachstum. Wir nutzen Facebook, weil dort fast alle unsere Freund:innen sind, wir nutzen Uber, weil dort so viele Fahrer:innen auf unsere Fahrtwünsche antworten, etc. Diese Tatsache führt zu der Rückkopplung, dass Plattformen immer nützlicher werden, je mehr Leute an ihr partizipieren. In der Ökonomie nennt man diesen Zusammenhang „Netzwerkeffekt“ oder „Netzwerkexternalität“, ich aber nenne es mit David Singh Grewal „Netzwerkmacht“ (Grewal 2008).
Diese Netzwerkmacht wäre allerdings nur schwer zu in tatsächlichen Einfluss umzumünzen, wenn die Plattform nicht auch fähig wäre, Kontrolle auszuüben. Alle Akteure auf der Plattform können von der Plattform mal mehr mal weniger subtil in ihren Interaktionen beeinflusst werden. Über das Anbieten oder nicht Anbieten bestimmter Funktionen, über die Regulierung des Zugangs, über das Design des Nutzerinterfaces, über die Steuerung von Sichtbarkeit von Interaktionsmöglichkeiten über Algorithmen und einige andere Hebel kann die Plattform zumindest grob lenken, welche Interaktionen wahrscheinlich werden und welche nicht (Seemann 2021). Beides zusammen – Netzwerkmacht und Kontrolle – ergibt das, was ich Plattformmacht nenne.
Doch wie kommen Plattformen überhaupt an diese Macht? Wie haben sie es geschafft, sich jeweils zwischen uns und unsere wechselseitigen Abhängigkeiten zu schieben und diese Abhängigkeiten auf sich zu beziehen? Die Antwort ist: zumindest initial nehmen sie sich diese Macht einfach.
Plattformen treten nie in einen machtleeren Raum. Es gab Freundschaften vor Facebook, Personentransport vor Uber und Unterhaltungsangebote vor Netflix. Das Erste, was eine Plattform also macht, ist, bestehende Interaktionsnetzwerke und ihre impliziten Abhängigkeiten zu analysieren, um sie für sich einzunehmen. „Einnehmen“ muss hier im quasi-militärischen Sinne verstanden werden. Während Staaten Territorien kontrollieren, kontrollieren Plattformen Netzwerkgraphen und während die Macht der Staaten auf einer initialen Landnahme beruht (Schmitt 1950), beruht die Macht der Plattformen auf einer initialen Graphnahme (Engemann 2016 u. 2020). Das funktioniert, weil Netzwerkgraphen selten aus gleichverteilten Knoten und Verbindungslinien bestehen, wie ein Maschendrahtzaun, sondern in Wirklichkeit zerklüftete Landschaften von akkumulierten Verbindungen, Interaktionen und Abhängigkeiten sind und daher ebenso strategisch angegangen werden können, wie Landschaften. Facebook zum Beispiel eroberte in seiner Gründungsphase zunächst nur die Studierenden der Harvarduniversität, indem es sie einlud, ihre Freundschaften auf Facebook weiterzuführen. Erst nach Einnahme des Harvardgraphen nahm Facebook weitere Universitäten ins Visier. So ging es weiter, ein Campus nach dem anderen. Und erst, als es durch die Graphnahme der US-Studentenschaft so viel Netzwerkmacht aufgebaut hatte, dass alle Teil des Netzwerkes werden wollten, öffnete Facebook sich der Allgemeinheit (Seemann, S. 159 f).
Die Struktur des Gesundheitsgraphs
Wie kann eine solche Graphnahme also im Gesundheitsbereich aussehen? Auch das Gesundheitssystem ist kein machtleerer Raum, sondern auch er ist schon strukturiert durch ein komplexes Geflecht wechselseitiger Abhängigkeiten unterschiedlicher Akteure. Um ein Bild der Lage zu bekommen, muss der vorhandene Gesundheitsgraph zumindest grob umschrieben werden. Die Frage lautet: Was sind die strategisch wichtigen Abhängigkeiten, die als Einfallstor dienen können?
Das Gesundheitssystem ist groß und komplex und schon länger nicht mehr unberührt von Plattformunternehmen. Sei es Apple und Google mit ihren Health-Apps und Trackingdevices (Maschewski/Nosthoff 2019), seien es populäre Gen-Datenbanken wie 23andme, seien es immer mehr plattformisierte Hersteller elektronischer Prothesen und digital gesteuerter Hilfsmittel wie Cochlea-Implantate, Herzschrittmacher oder automatische Insulinpumpe. Hinzu kommen Portale wie Doctolib zur Terminfindung bei lokalen Ärzt:innen und/oder Dienste für Telemedizin wie Kry.
Doch all diese Plattformisierungen arbeiten sich bislang nur an Teilbereichen des Gesundheitsgraphen ab. Der große Gesundheitsgraph – die großen Linien der relevanten Abhängigkeitsverhältnisse – sind noch immer dieselben wie vor 50 Jahren. Sie gilt es genauer zu strudieren, wenn wir die Möglichkeit des Ernstfalls, der vollständigen Graphnahme, ausloten wollen.
Unter den miteinander verschränkten Akteuren – die niedergelassenen Ärzt:innen, die Krankenhäuser, die Pharmaindustrie, die Krankenversicherungen (gesetzliche wie private), den Pflege- und Kur-Einrichtungen, die Apotheken und natürlich den Patient:innen – ist eine Beziehung ganz besonders herausgehoben: die zwischen Ärztin und Patient:innen. Die (Haus-)Ärztin ist für gewöhnlich der erste und der letzte Kontakt der Patientin mit dem Gesundheitssystem. Die Ärztin ist gewissermaßen das Interface, über den die Patientin auf das Gesundheitssystem zugreift. Es ist die Ärztin, die die Diagnosen erstellt, Therapien und Medikamente verschreibt und gegebenenfalls an Spezialist:innen oder ins Krankenhaus weiter verweist. Das Arzt-Patienten-Verhältnis ist geprägt von Vertrauen und nicht selten von persönlichen Beziehungen. Es ist nicht umsonst seit Jahrhunderten durch Kodizes wie den Hippokratischen Eid und gesetzlichen Regelungen, wie die ärztliche Schweigepflicht besonders geschützt. Es ist zudem kein Zufall, dass Ärzt:innen massiv im Lobbyfokus aller anderen Akteure des Gesundheitssystems stehen. Insbesondere die Pharmakonzerne investieren enorme Mengen an Geld in den Aufbau von Beziehungen zu Ärzt:innen, spendieren ihnen Reisen, Konferenzen oder teure Werbegeschenke. 2016 besuchten ca. 15.000 Pharmavertreter:innen jährlich 20 Millionen Mal deutsche Praxen und Krankenhäuser (Viciano 2017). Es dürften seitdem nicht weniger geworden sein.
Auch andere Akteure des Gesundheitsbereichs sind einflussreich. Die Pharmakonzerne verfügen über eine Menge Geld und Lobbypower. Die Versicherungen sitzen an der Schaltstelle der Entscheidung, welche Medikamente und Therapien wie vergütet werden (zumindest im Rahmen politischer Regulierung). Auch das sind strategisch wichtige Engstellen, die eine Menge Abhängigkeiten auf sich vereinen, jedoch reicht keiner dieser Punkte in ihrer Wichtigkeit an das Arzt-Patienten-Verhältnis heran. Wir stellen fest:
Wer den Gesundheitsgraphen kontrollieren will, muss das Arzt-Patienten-Verhältnis kontrollieren.
Der offensichtliche Angriff wäre demnach, die Ärzt:innen auf die eigene Seite zu ziehen. Das ist das, was die Pharmaindustrie mit ihrem Milliarden Euro teuren Kampagnen seit Jahrzehnten mit gemischtem Erfolg versucht. Auch die Krankenkassen haben im Ansatz bereits „ihre“ Ärzt:innen. Die gesetzlichen Versicherungen in Form der Kassenärzt:innen und die Privaten haben zumindest die Ärzt:innen für plastische Chirurgie praktisch exklusiv. Doch einerseits ist die Gruppe der Ärzt:innen, die alle Arten von Patient:innen abdecken immer noch die mit Abstand größte und anderseits haben die Krankenkassen aufgrund der strengen Regulierung sowieso nur vergleichsweise wenig Spielraum, ihren Einfluss auszunutzen.
Das Gezerre um die Ärzt:innen selbst wäre allerdings gar nicht notwendig, gelänge es, die Macht der Ärzt:innen selbst zu brechen, indem man sie zum austauschbaren Teil des Systems macht. Keiner der traditionellen Akteure im Gesundheitssystem ist in der Lage, das zu erreichen. Doch eben hier kommt die Macht der Plattformen ins Spiel.
Voraussetzungen für die Graphnahme des Gesundheitssystems
Wenn ein Beziehungsgeflecht noch in undigitalisierter, das heißt nicht digital operationalisierbarer Form vorliegt, dann empfiehlt sich für die Graphnahme die Strategie des Iterationsangriffs (Seemann 2021, S. 172). Beim Iterationsangriff werden in einem ersten Schritt die vorhandenen Beziehungsgeflechte digital in einer zentralen Datenbank erfasst. Auf dieser Grundlage kann dann eine Kontrollebene eingezogen und den jeweiligen Interaktionspartner:innen angeboten werden. Die neue Kontrollebene wirbt zum Beispiel damit, die Interaktion zu vereinfachen (Reduzierung der Koordinationskosten), Vertrauensverhältnisse zu ersetzen und/oder mehr Auswahl an potentiellen Interaktionspartner:innen verfügbar zu machen. Alle drei Vorteile hängen unmittelbar miteinander zusammen. Wird das Angebot angenommen, finden die Interaktionen von nun an auf der neuen, digitalen Plattformebene statt. Die vorherrschenden Abhängigkeiten wurden also in Abhängigkeit zur Plattform transformiert. Der Graph wurde vertikal iteriert (Seemann 2021, S. 67 f).
Im Ansatz geschieht das bereits mit Plattformen wie Doctolib. Doctolib ist ein französisches Unternehmen, das seit sieben Jahren eine Datenbank mit Ärzt:innen über eine Website oder App verfügbar macht, um Terminvereinbarungen zu vereinfachen. Das bereits mit über einer Milliarde Euro bewertete Unternehmen ist seit einiger Zeit auch in Italien und Deutschland erfolgreich. Während der Pandemie hat es seinen Umsatz um 50% gesteigert, auf €200 Millionen Euro (Abboud 2021). Doctolib hat es verstanden, Ärzt:innen zu überzeugen, ihre Terminvereinbarung auf die Plattform auszulagern. Gleichzeitig schätzen auch die Patient:innen den Komfort, nicht erst umständlich anrufen zu müssen, um einen Termin zu vereinbaren.
Das ist allerdings noch keine Graphnahme. Die Terminbuchung wird zwar von vielen als nützliche Ergänzung angenommen, verändert die Arzt-Patienten-Beziehung aber noch wenig. Doch es ist ein Fuß in der Tür. Die wichtigsten drei Angriffsvektoren für eine mögliche Graphnahme zeichnen sich bereits ab:
Koordinationskosten. Plattformen sind häufig sehr gut darin, Koordinationskosten – also den Aufwand sich zu koordinieren – radikal zu reduzieren. Exakt diesen Einfallsvektor hat Doctolib bereits erfolgreich gespielt. Für beide Seiten, für Patient:innen und Ärzt:innen reduzieren sich die Koordinationskosten bei der Terminvergabe enorm und es ist derzeit der wichtigste, wenn nicht einzige Grund, warum die Plattform so erfolgreich ist.
Auswahl. Die reduzierten Koordinationskosten können nun in einem zweiten Schritt zu Second Order Effekten führen, zum Beispiel, dass Patient:innen eine gefühlt größere Auswahl an potentiellen Ärzt:innen in ihrer Umgebung zur Verfügung haben. Durch leichtere Auffindbarkeit und durch die schnelle Buchbarkeit fällt die Hürde, neue Ärzt:innen auszuprobieren. Wenn man unzufrieden ist, die eigene Ärztin über Wochen ausgebucht ist, oder man sich schlicht eine zweite Meinung einholen will, kann man nun schnell die Ärztin wechseln.
Vertrauen. Die wichtigste Ressource des Arzt-Patienten-Verhältnisses ist allerdings Vertrauen. Oft wurde es über viele Jahre aufgebaut. Man kennt sich, man grüßt sich auf der Straße, hält bei Besuchen einen kleinen Schnack, fragt nach der Familie. Das ist die schwierigste Hürde. Erst wenn es gelänge, eine Alternative zu diesem Vertrauensverhältnis attraktiv zu machen, kann eine Graphnahme gelingen. Das ist schwierig, aber nicht unmöglich, da Doctolib keinen vollen Ersatz für dieses Vertrauen bieten muss, nur hinreichend viel, dass die oben genannten Vorteile den Ausschlag geben. Plattformen können ebenfalls Vertrauen herstellen, indem sie z.B. Ärzt:innen bewertbar machen, Patientenrezensionen anzeigen und/oder eigene Prüfverfahren und Qualitätssigel einführen. Das Ziel müsste sein, das Vertrauen zum Teil auf die Plattform zu transferieren.
Die verschiedenen Angriffsvektoren wirken auf die beteiligten Akteursgruppen unterschiedlich stark. Während die Senkung der Koordinationskosten auf beiden Seiten – den Ärzt:innen wie den Patient:innen – wirkt, sind Auswahl und Vertrauen nur für die Patient:innen-Seite gute Argumente. Für Ärzt:innen ist die Aussicht auf mehr Patient:innen“ nur theoretisch attraktiv. In der momentanen Situation laufen Ärzt:innen kaum Gefahr, zu wenig Patient:innen zu haben. Eher im Gegenteil. Auch das Vertrauensverhältnis ist ausschließlich auf Patient:innen-Seite wichtig.
Eine spekulative Roadmap zur Graphnahme
Doctolib ist also in einer strategisch günstigen Ausgangslage, müsste aber einiges tun, um eine ernsthafte Graphnahme anzustreben. Ein Bewertungs- und Rezensionssystem für Ärzt:innen wird mit Doctolibs aktuellen Geschäftsmodell kaum möglich sein. Derzeit verlangt das Unternehmen € 129 von den Ärzt:innen, um über das Portal buchbar zu sein. Für diesen Betrag wollen die Kund:innen natürlich keine Kritik über sich auf der Plattform lesen. Das erste, was Doctolib also tun müsste, wäre dieses Geschäftsmodell aufzugeben und wahrscheinlich erstmal ganz auf Einnahmen verzichten, um risikokapitalfinanziert auf den neuen Kurs einzuschwenken. Eine Bewertungsfunktion zu implementieren und generellen Erfahrungsaustausch unter den Patient:innen zu ermöglichen wäre demnach der zweite Schritt. Dadurch könnte ein Teil des Vertrauens auf die Plattform übergehen und das Arzt-Patient-Verhältnis würde sehr viel volatiler.
Ob das für die Graphnahme ausreicht, ist unklar. Aber von hier aus, wären einige weitere Maßnahmen denkbar.
Weitere Volatilität im Arzt-Patienten-Verhältnis könnte durch weitere Features erreicht werden. Etwa eine von der Plattform garantierte Sofortbehandlung. Der Algorithmus sucht den nächstbesten Termin aus den freien Terminen aller Ärzt:innen im Umkreis von 5 Km heraus und bucht automatisch den frühest verfügbaren. Eine andere Möglichkeit wäre die zweite Arztmeinung als unabdingbaren Standard zu promoten.
Eine weitere Reduzierung von Koordinationskosten bringt die weitflächige Einführung von Telemedizin. Doctolib könnte sich mit erfolgreichen Anbietern zusammentun und eine eigene Anwendung dazu direkt implementieren, so dass man aus der App oder Website heraus, sofort Videosprechstunden abhalten und Untersuchungsergebnisse teilen und besprechen kann.
Wenn man nun für viele Patient:innen die allgemeine Schnittstelle zum Gesundheitssystems geworden ist, lässt sich das Angebot weiter ausbauen und optimieren. Eine Möglichkeit dazu wäre das Angebot einer vorgeschalteten Diagnose-KI, die zum Beispiel Voruntersuchungen bei bestimmten Standardbeschwerden macht und so schon mal grob den Möglichkeitsraum von Diagnosen vorsortiert. Erst nach Konsultation der Diagnose-KI wird man dann auf die passenden Ärzt:innen weiterverwiesen, die dann ihrerseits nicht bei null anfangen müssen.
Es lassen sich weitere Elemente in das neue Gesundheitsinterface einpassen. Doctolib könnte das einheitliche Interface für die digitale Patientenakte, die E-Rezepte und andere digitalisierte Gesundheitsformate werden, wo man genau verwalten kann, welche Ärzt:innen auf welche Daten Zugriff haben. Dazu wäre auch gleich eine Schnittstelle zu einer Online-Apotheke denkbar, um gleich aus dem Interface heraus die Medikamente zum Rezept zu bestellen.
Zuletzt wäre auch eine Integration mit den Versicherern möglich, so dass nicht nur die bisherigen Behandlungen transparent werden, sondern auch die Behandlungsoptionen und deren eventuelle Zusatzkosten je Diagnose eingeblendet werden. Das Einreichen von Rechnungen wäre so ein Kinderspiel. Eventuell wäre sogar der Wechsel des Tarifs, oder gar des Versicherers aus dem Interface heraus möglich.
Am Ende wäre es auch der logische Ort, wo man seine sequenzierten Gen-Daten hinterlegt, um personalisierte Empfehlungen, Rezepte, Hinweise, sogar Warnungen zu bekommen.
Fazit
Die Digitalisierung im Gesundheitssystem hat das Potential die Prozesse sehr viel effizienter und reibungsfreier zu machen, die Forschung voran zu treiben und den Patient:innen mehr Optionen, bessere Versorgung und mehr Entscheidungsfreiheit zu geben. Doch all das zieht einen tiefgreifenden Wandel in den Abhängigkeits- und damit Machtstrukturen des Sektors nach sich. In anderen Feldern und Branchen ist bereits zu sehen, wie Plattformen sich diese Neuaushandlung zunutze machten. Durch ihr Prinzip der Integration von Beziehungen, schaffen sie es, sich als neue, allumfassende Intermediäre zwischen die jeweiligen Parteien zu stellen und so alle Abhängigkeiten auf sich zu beziehen.
Auch im Gesundheitsbereich könnte sich eine solche Entwicklung vollziehen und im Ansatz ist sie schon beobachtbar. Ob sie so verlaufen wird, wie ich es hier dargelegt habe, ist zu bezweifeln. Vielleicht wird es auch ganz anders laufen und ein ganz anderer Player tut etwas völlig anderes, um den Graph einzunehmen. Vielleicht wird der Gesundheitsbereich auch von der Plattformisierung weitgehend verschont, wer weiß? Mir ging es nur darum, die Möglichkeit einer vollständigen Graphnahme plausibel zu machen und die Mechanismen und strategischen Punkte aufzuzeigen, die dabei eine Rolle spielen könnten. Wenn dieses Zukunftsszenario genauso verlockend, wie erschreckend wirkt, dann zeugt das nur für seine Realitätsnähe.
Festzuhalten ist, dass der kritischste Punkt unseres kleinen Planspiels das Vertrauen der Patient:innen ist. Eine Plattform kann nur erfolgreich sein, wenn es ihr gelingt, einen ausreichenden Teil des Vertrauens auf sich selbst zu transferieren. Das gelingt um so besser, je weniger Vertrauen in die traditionellen Akteure vorhanden ist. Insbesondere die staatliche Regulierung spielt hier eine Schlüsselrolle. Wenn es dem Staat und den dabei eingebundenen Stakeholdern nicht gelingt, eine digitale Infrastruktur (mit elektronischer Gesundheitskarte, -Akte, -Rezept, usw.) anzubieten, die den Patient:innen das Gefühl gibt, dass ihre Bedürfnisse und ihre Sicherheit im Zentrum stehen, werden externe Plattformplayer diese Diskrepanz um so leichter auszunutzen wissen. Darauf sollten sich alle Akteure des Gesundheitssystems entsinnen, wenn sie in die nächsten Verhandlungen gehen.
Engemann, Christoph (2016) Digitale Identität nach Snowden – Grundordnungen zwischen deklarativer und relationaler Identität. In: Hornung, Gerrit; Engemann, Christoph (Hrsg.): Der digitale Bürger und seine Identität, Baden-Baden 2016.